No.5
标签:自监督脑EEG到图像解码框架
前言
《NeuroBridge: Bio-Inspired Self-Supervised EEG-to-Image Decoding via Cognitive Priors and Bidirectional Semantic Alignment》
会议:AAAI 2026
年份:2025.11
分区:CCF A类会议
作者:Wenjiang Zhang, Sifeng Wang, Yuwei Su, Xinyu Li, Chen Zhang, Suyu Zhong
主要单位:Beijing University of Posts and Telecommunications
自监督的脑电信号(EEG)到图像解码框架,旨在弥合神经信号与视觉内容之间的模态鸿沟。
一、研究背景与动机
1. 问题背景
视觉神经解码:目标是从大脑活动(如EEG)中重建或推断感知的视觉刺激,对理解人类视觉认知和脑机接口应用具有重要意义。
EEG → Image 的对齐不是“模型不够大”,而是 语义空间严重不匹配 + 数据极少 + EEG 本身高度不稳定。
两个“不可忽视的鸿沟”
(1)动态感知差异(Dynamic Variability Gap)
- 同一张图
- 不同人 / 同一人不同时间
- EEG 响应完全不同
- 👉 注意力、状态、噪声、个体差异
EEG 的“不稳定性不是噪声,而是认知状态变化”。(2)静态模态鸿沟(Static Intrinsic Gap)
- EEG:低维、时序、噪声大
- Image:高维、空间结构、语义密集
- 👉 直接做对比学习,本质是 把“脑信号”硬塞进“语言-视觉语义空间”
2. 现有方法局限性
- 数据稀缺:高质量“刺激-脑响应”配对数据有限。
- 模态鸿沟:EEG(时间性、低维、噪声多)与图像(空间性、高维、语义丰富)之间存在结构和语义上根本差异。
- 单向对齐不足:现有方法多侧重于单向对齐或单模态增强,缺乏双向协同建模。
二、核心贡献
1. 整体思想
NeuroBridge 不是一个“新模型”,而是一个 “对齐策略框架”
它的贡献不是:新encoder、新 loss、新网络结构
而是 两条 “生物启发式”的工程级设计原则
2. 两个核心模块
(1)CPA(Cognitive Prior Augmentation)
💡 CPA 的本质不是普通的数据增强。
作者的关键洞察:许多“人类对图像的认知不变性”,可以被模拟为一种 认知先验,而不是“分类增强”。
1️⃣ Image 侧:多视角、语义保持的增强(很重要)
✅ 有效的增强:Gaussian Blur、Gaussian Noise、Low Resolution、Mosaic
❌ 有害的增强:Color Jitter、Grayscale、Random Crop
原因不是工程,而是认知:
人类视觉对 颜色是敏感的,裁剪会破坏“语义整体性”

2️⃣ EEG 侧:极度克制(这是成熟点)
EEG 只用 一个增强,而不是多视角:
smoothing 是唯一稳定有收益的
作者明确承认:
EEG 没有“可迁移的大规模先验”,乱增强只会破坏时序语义
👉 这是和很多“暴力 EEG augmentation 论文”的关键分水岭
设计的生物学合理性:
人类看图像时:
同一幅”猫”的图像
不同人/不同时间看到的是:
- 注意力焦点不同(→裁剪增强)
- 视觉清晰度不同(→模糊/低分辨率增强)
- 记忆完整度不同(→马赛克增强)
大脑产生EEG时:- 无论个体差异如何,对”猫”的概念表征,在神经层面有一定的核心稳定模式
- 外在表现可能有噪声,但内在语义核心稳定 → 只需平滑去噪,保留核心模式

(2)SSP(Shared Semantic Projector)
💡 SSP 想解决什么?
CLIP 的视觉空间:
本质是 语言主导的语义空间
而 EEG 是 感知-神经动力学空间
直接对齐 = 语义歪曲
SSP 的策略不是“强行对齐”,而是:
让 EEG 和 Image 都“退一步”,进入一个 “可学习的中间语义空间”
关键设计点:
1️⃣ Image encoder 冻结
保留大规模语义结构
防止小 EEG 数据“拉歪 CLIP”2️⃣ 双投影器(pI, pE)
EEG:主动适配
Image:轻微可塑3️⃣ 非对称归一化(非常聪明)
Image embedding:ℓ2 normalize
EEG embedding:不归一化👉 EEG embedding 的 模长 = 置信度
👉 方向 = 语义
这是论文里一个被低调写,但非常高级的设计。
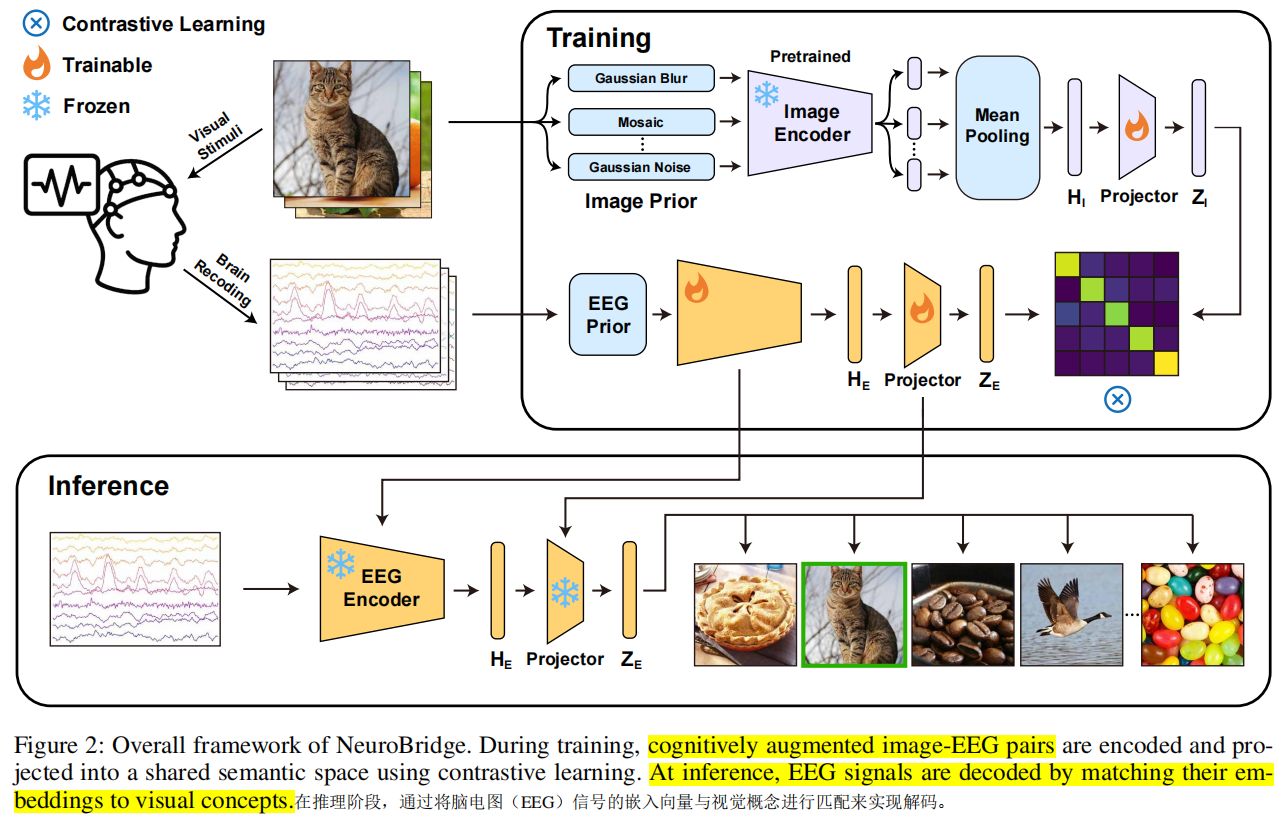
3. 训练策略
(1)训练流程
- 输入:配对EEG-图像数据。
- CPA增强:分别对图像和EEG施加多种变换。
- 特征提取:
- 图像:使用预训练的CLIP编码器(冻结权重)。
- EEG:使用可训练的编码器(如EEGProject)。
- 语义聚合:多视图图像特征取平均。
- SSP投影:将两类特征映射到共享语义空间。
- 模态感知对比学习:通过对比损失对齐正样本、分离负样本。
损失函数特点:
非对称归一化:仅对图像特征做L2归一化,EEG保持原始幅度,以保留其动态信息。
支持语义对齐的同时保持EEG特征的表达能力。
双向对比损失:
Image → EEG
EEG → Image
但注意:不是完全对称,是 语义方向一致 + EEG 强度可学习
4. 论文亮点
1️⃣ 把 EEG 不稳定性当“认知信号”,不是噪声
2️⃣ Image 的增强 ≠ 分类增强,而是“认知等价变换”
3️⃣ 不要强行把 EEG 塞进 CLIP 空间,要造缓冲层
- 生物启发的自监督架构:模拟认知变异性与跨模态协同适应。
- 非对称增强策略:针对不同模态设计差异化增强,提升语义对齐。
- 共享语义投影与双向对齐:有效弥合EEG与图像之间的模态鸿沟。
- 强泛化能力:在零样本、跨被试、跨数据集(EEG/MEG)场景下均表现优异。
5. 局限性
❗ CPA 是 人工设计的认知先验
不一定覆盖真实脑认知变化❗ 强依赖 CLIP
本质还是“语言视觉霸权”❗ 仍然是 retrieval
不是生成,不是时间连续建模
6. 补充知识
(1)zero-shot scenario
模型在训练阶段从未见过的类别上进行测试或推断的任务设置
与“传统分类”的对比:
传统监督学习:
训练: 模型学习将输入数据(如图像)映射到一组已知的标签(如“猫”、“狗”、“车”)。
测试: 模型对属于这组已知标签的新数据进行分类。
核心: 训练和测试的类别是完全相同的。零样本学习:
训练: 模型学习的是一种更通用的能力——理解不同事物(概念)之间的语义关系或相似性,而不是记忆特定的类别标签。
测试: 模型需要处理或识别在训练数据中从未出现过的新类别。它必须利用训练时学到的通用语义知识,将新样本与这些新概念进行匹配。
核心: 训练和测试的类别是互斥的、完全不同的。在本文(NeuroBridge)中的应用
在 NeuroBridge 这篇论文中,任务被明确定义为 “zero-shot neural visual decoding” 或 “200-way zero-shot retrieval”。具体设置如下。
训练集: 使用 1,654 个 视觉概念(例如,1,654 种不同的物体或场景类别)。每个概念有对应的图像和诱发的大脑信号(EEG)。
测试集: 使用一个完全独立的、在训练中从未出现过的 200 个 新概念。为什么零样本设置如此重要和具有挑战性?
- 现实意义: 人脑能够轻松识别和理解从未见过的新物体(例如,你第一次见到某种奇特的海洋生物也能大概描述它)。因此,零样本能力是迈向“通用”或“类人”人工智能的关键一步。
- 评估泛化能力: 零样本是测试模型是否真正学会了可迁移的、深层的语义知识,而非只是记住了训练数据的模式(即过拟合)的最严格标准之一。
- 数据稀缺问题的应对: 在脑机接口领域,收集海量、涵盖所有可能类别的大脑信号数据是不现实的。零样本学习使模型能够利用有限的数据学习通用映射规则,并推广到新类别。
(2)对比学习中温度参数 $τ$
温度参数 $τ$ 是一个标量值(通常 < 1,如论文中的 0.07),用于调节相似度分数的分布锐度。
在对比损失函数中,它出现在softmax的指数部分:
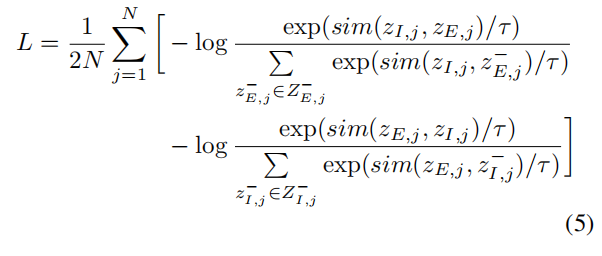
$τ$ 控制着相似度分数在计算概率时的“缩放”程度
$τ$ 很小(如 0.07) → 高倍放大镜
- 相似度差异被显著放大
- 模型需要更精确地区分正负样本
- 学习更困难但更精细的特征
$τ$ 很大(如 1.0) → 低倍放大镜
- 相似度差异被压缩
- 模型对正负样本的区分要求更宽松
- 学习更泛化但可能粗糙的特征
论文中 $τ$ 设置为 0.07,这是一个非常小的值,意味着:
- 强制精确的跨模态对齐
- EEG信号和图像特征必须高度相似才能被识别为正对
- 模型被迫学习更细微、更本质的语义对应关系
- 有助于克服EEG噪声大、信息稀疏的问题
- 提高零样本泛化能力
- 缓解模态鸿沟的负面影响
- EEG和图像特征来自完全不同的分布
- 如果没有$τ$的调节,它们的相似度分数可能普遍较低且差异小
- 小$τ$放大这些差异,使得即使绝对相似度不高,相对差异也能被有效利用
- 温度$τ$对损失函数梯度的影响
从优化角度看,$τ$直接影响梯度的大小:
$∂_L/∂_sim∝1/τ$
$τ$越小 → 梯度越大 → 更新越激进
这对于NeuroBridge特别重要:
正样本对(正确配对的EEG-图像)需要被快速拉近
负样本对需要被快速推远
小$τ$加速这个过程,帮助模型快速建立跨模态联系



