No.12
标签:脑启发式注视引导神经视频交叉模态深度融合目标检测
前言
《Brain-inspired gaze-guided neuro-video cross-modal deep fusion for object detection in degraded videos》
期刊:Expert Systems With Applications
年份:2026
分区:Q1,一区Top;IF:7.5
作者:Manyu Liu, Ying Liu, Wenao Han, Aberham Genetu Feleke, Weijie Fei, Luzheng Bi
主要单位:School of Mechanical Engineering, Beijing Institute of Technology
- 提出一个面向降质 UAV 视频目标检测的脑机协同系统:
当视频质量差、纯视觉模型容易失效时,引入人的 EEG 脑电信号和眼动注视信息,通过跨模态融合提升目标检测;
当视频质量好时,则尽量使用纯计算机视觉,以降低人的认知负担。
一、研究背景与问题定位
1. 背景
- 关注的是降质视频中的目标检测,典型场景是 UAV 侦察或监控视频。
- 视频可能受到运动模糊、云雾遮挡、低照度、噪声、压缩伪影等影响,导致传统视觉检测模型性能下降。
- 论文认为,人类视觉系统在低质量视觉条件下仍有较强的目标感知能力,但纯人工判读效率低、负担大,因此需要一种 **“人脑认知能力 + 机器视觉效率”**的协同方案。
2. 问题定位
- 不是单纯做一个更强的视觉检测器,而是利用 EEG 和眼动,把人的隐性目标感知信息引入检测系统。
二、方法主线
1. 注视引导的多模态对齐
EEG 和图像的融合难点在于:EEG 是神经反应,图像是外部刺激,两者很难知道“哪段脑电对应图像中的哪个区域”。作者用眼动信号解决这个问题:记录被试的注视点,以注视点为中心裁剪 400×400 的图像区域,同时取对应时间窗的 EEG 信号,这样让视觉特征和神经特征在语义上对齐。
这个设计是全文最关键的脑机接口逻辑:
眼动不是最终判别信号,而是作为 EEG 与图像之间的对齐锚点。
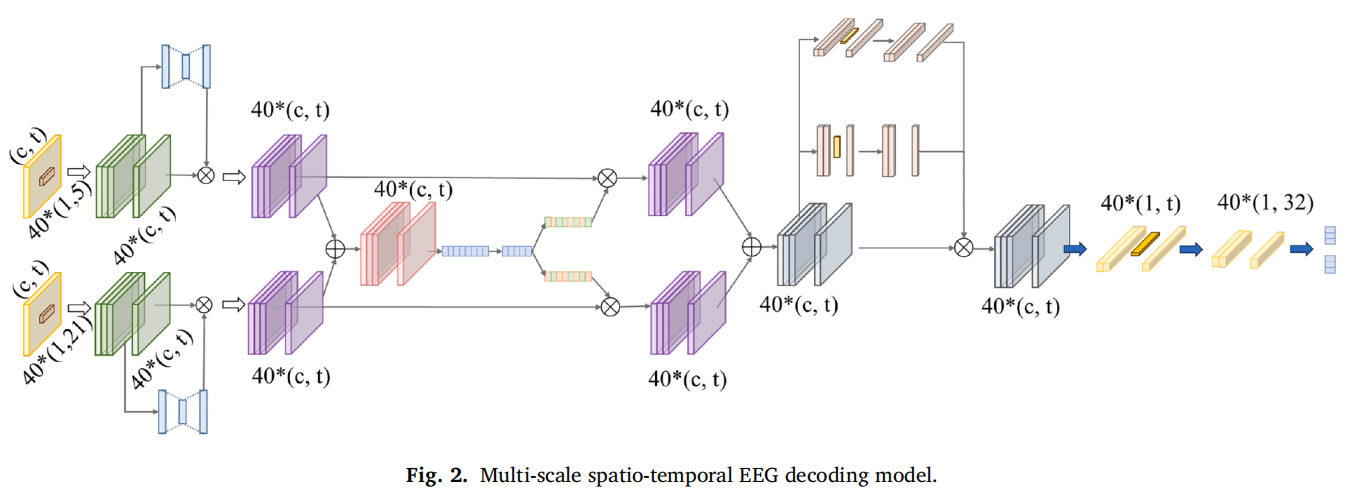
2. MSST-Net:多尺度时空EEG解码网络
MSST-Net 是 EEG 解码的基础模型。它主要包括两个思想:
第一,使用不同大小的卷积核提取不同频段相关特征。论文中使用 kernel size 为 5 和 21 的分支,意图分别覆盖较高频和中低频信息,并通过类似 SK-Net / SE-Net 的注意力机制自适应分配权重。
第二,加入局部时空特征提取模块,包括 ELA 注意力、空间卷积、批归一化、平方激活、对数激活、平均池化和 Dropout,用于捕捉 EEG 的通道拓扑关系和时间动态。
MSST-Net 想解决 EEG 信噪比低、个体差异大、时频结构复杂的问题。 低质量目标检测中,EEG 里的 θ、α、β、γ 等频段可能分别对应注意分配、目标识别、视觉处理和决策过程,因此多尺度设计是合理的。
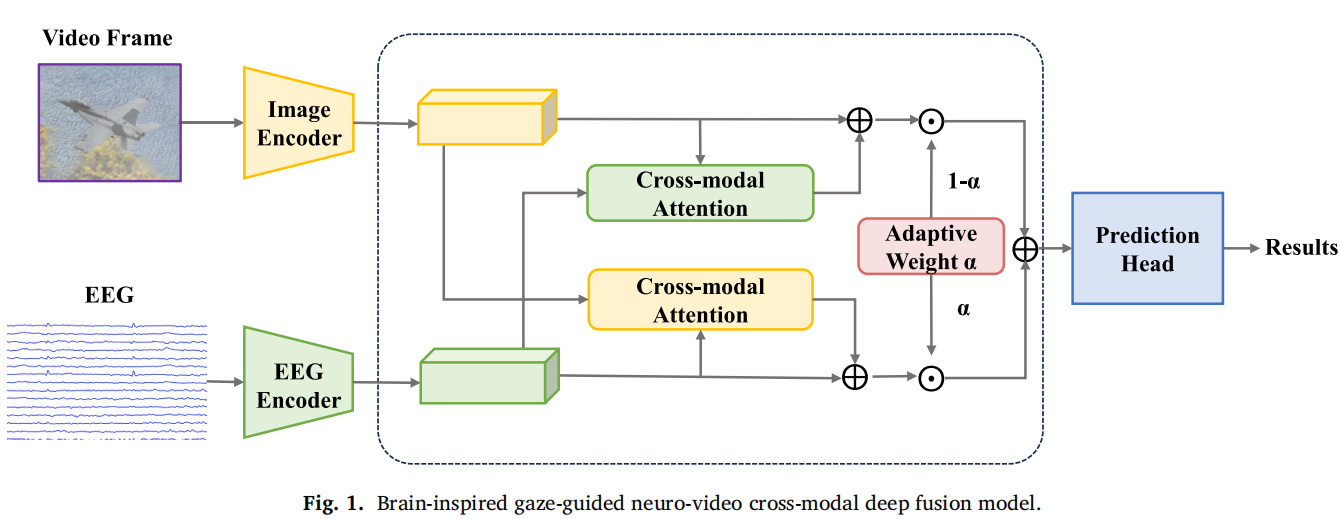
3. NCF-Net:神经视频交叉模态融合网络
NCF-Net 同时输入 EEG 特征和图像特征。
图像分支使用 MobileNetV3 提取以注视点为中心的图像区域特征;EEG 分支使用 MSST-Net。
然后通过 cross-modal attention 让两个模态互相增强,最后用自适应权重 α 融合 EEG 与图像特征。
- 它的融合公式本质是:
视觉特征帮助增强 EEG 特征;
EEG 特征帮助增强视觉特征;
再通过可学习权重决定最终更依赖哪一类信息。
这一点比简单 concat 或 sum 更合理,因为在不同视频质量下,两类信息的可靠性并不相同:高质量视频时视觉特征更强,低质量视频时 EEG/眼动引导可能更有价值。
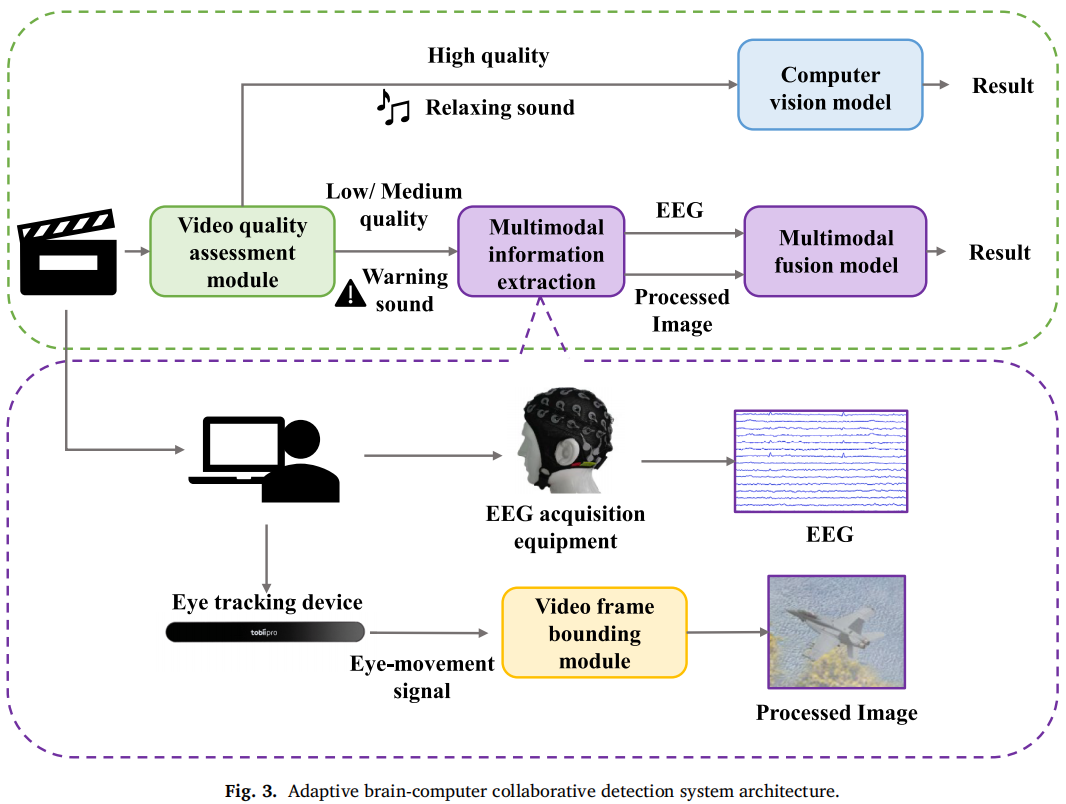
4. 自适应脑机协同系统
系统先对每帧视频做质量评估,指标包括模糊、噪声和亮度。综合质量指标为:
C = αBlur + βNoise + γBrightness
论文中通过网格搜索选择权重 α=0.5、β=0.3、γ=0.2,说明作者认为模糊对检测影响最大。系统将视频分为低、中、高质量:
高质量时优先用纯视觉模型;低/中质量时启用 EEG + 眼动 + 图像融合模型。
连续 5 帧质量状态变化时,用声音提示被试调整注意状态。
这个机制的意义在于:
不是始终让人参与,而是在机器不可靠时才调用脑机融合,从而降低认知负担。
三、实验设计
实验视频模拟 UAV 视角,每段 25 秒,分辨率 1920×1080,内容包括飞机、船、云、岛屿和海浪,目标为飞机和船。
目标随机出现在第 6–14 秒,避免被试预判。数据集包括 120 个低质量、120 个中质量、120 个高质量视频,其中一半含目标。
被试共 8 人,4 男 4 女,21–26 岁。EEG 使用 64 通道设备,采样率 1000 Hz;眼动使用 Tobii Pro-Fusion,采样率 30 Hz,与视频帧率匹配。
作者做了三类实验:
离线实验:基于眼动注视点构造 EEG-图像样本对。
伪在线实验:用滑动窗口模拟实时检测。
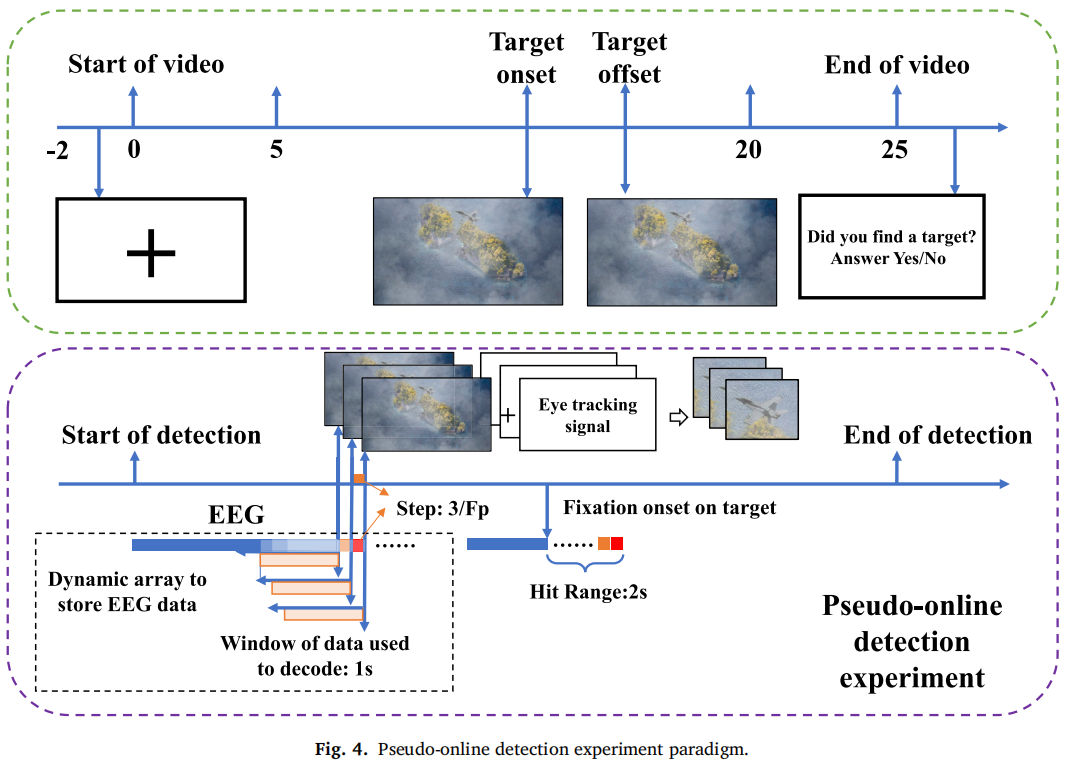
- 在线实验:真实闭环系统,实时采 EEG、眼动和视频帧并输出结果。
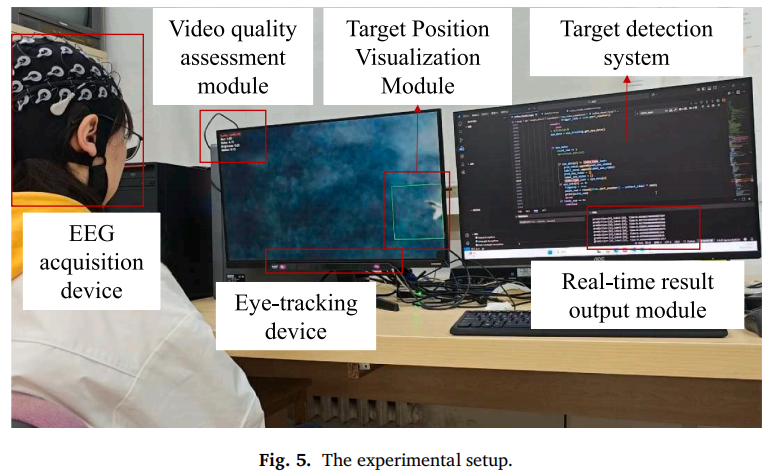
四、主要结果
1. MSST-Net设计的生理学依据
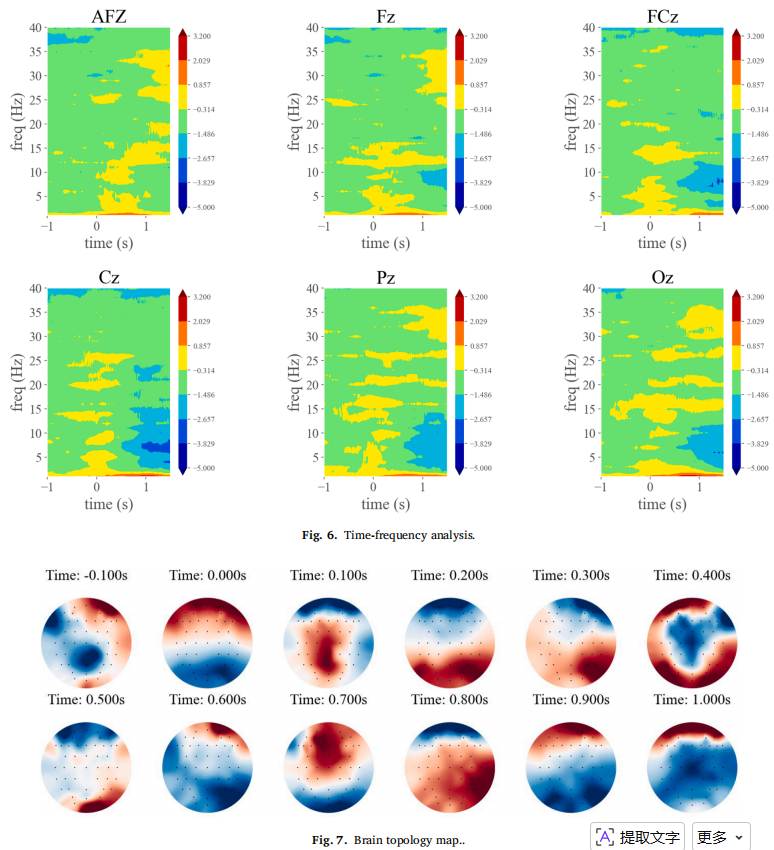
结果(图6)显示存在与层级化认知处理阶段相对应的振荡活动:
目标出现后,慢波活动(<5 Hz)显著增强,这与参与视觉目标识别的事件相关电位特征一致(Katz 等,2020),表明刺激被快速识别;
随后,在头皮各区域均检测到 𝛼(8-12 Hz)和 𝛽(12-20 Hz)频段的整体同步性增强,反映了空间注意力资源的分配及对目标注意力的集中(Bagherzadeh 等,2020; Fiebelkorn & Kastner ,2019);
此外,在Pz和Oz电极处观察到 𝛾 频段(25-40 Hz)活动持续增强,提示存在精细的视觉处理过程和持续的空间注意力;
值得注意的是,在AFz和Fz电极还发现了强而持久的γ同步现象,可能与目标识别后期阶段的高阶认知功能(如工作记忆更新和反应决策)相关(Kuzovkin 等,2018)。
这些频谱动态特征表明解码后的神经信号涵盖了从早期感知到高级认知的完整处理流程。该实证证据为采用自适应多尺度卷积核(见第2.1.2节)构建 MSST -Net提供了坚实的神经心理学基础。
为从空间角度进一步证实这些时域-频域特征的皮层起源,研究采用脑拓扑图谱分析(图7)来描绘目标处理过程中皮层激活的时空演变规律。激活模式呈现出明显的序列性进展:
在目标呈现后约0.1秒,激活主要集中于顶叶及中央区域,反映了早期的空间信息处理与注意力定向过程(Xu ,2018);
在0.2至0.6秒期间,激活焦点转移至顶枕区,并在0.2秒后出现显著的右侧偏侧化激活模式,这与空间搜索任务中观察到的右半球主导性一致;
该阶段特征与精细视觉特征分析及持续空间注意力机制相吻合(Bartolomeo & Seidel Malkinson,2019);
约0.7秒时,前额叶及中央区域出现显著激活,表明高级认知环节(如反应决策)已被激活(Qiu et al.,2018)。
不同时间点不同脑区的连续激活现象为 MSST 网络中通道注意力机制的设计提供了直接的神经科学依据。
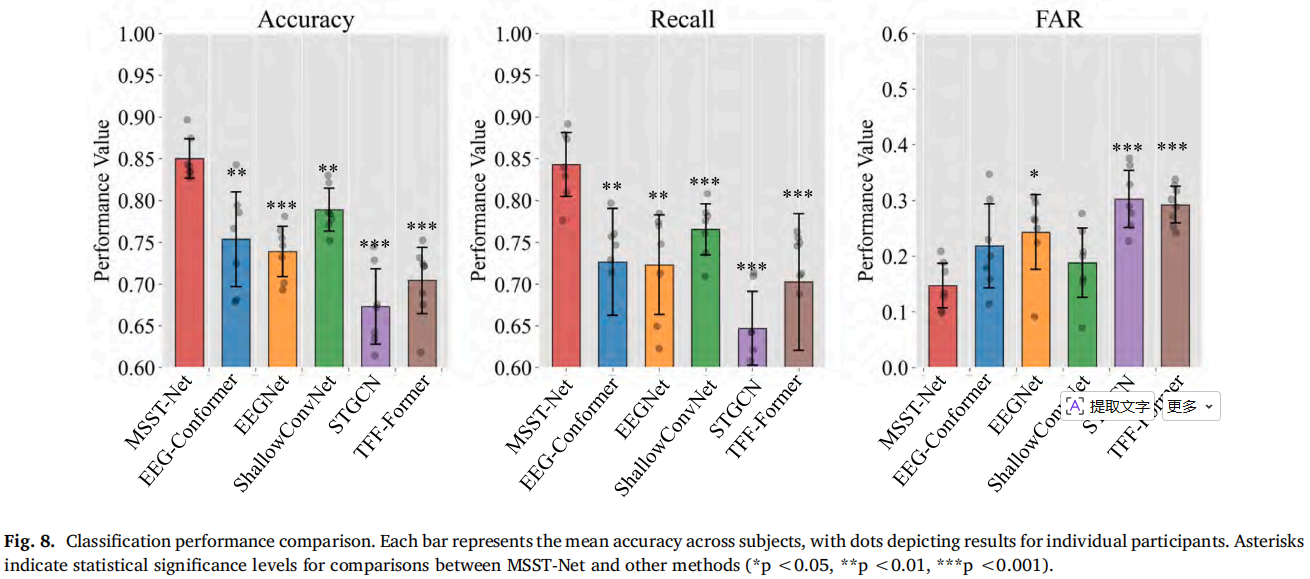
2. MSST-Net 明显优于 EEG 基线模型
MSST-Net 平均分类准确率达到 0.850±0.025,高于 EEG-Conformer、EEGNet、ShallowConvNet、STGCN 和 TFF-Former。其召回率为 0.828±0.045,误报率为 0.148±0.041,说明它在“发现目标”和“抑制误报”之间取得了较好平衡。
此外,在不同视频质量下,MSST-Net 表现较稳定:低质量 0.854,中质量 0.839,高质量 0.833。这一点说明 EEG 解码对于视频质量下降并不像纯视觉那样敏感。
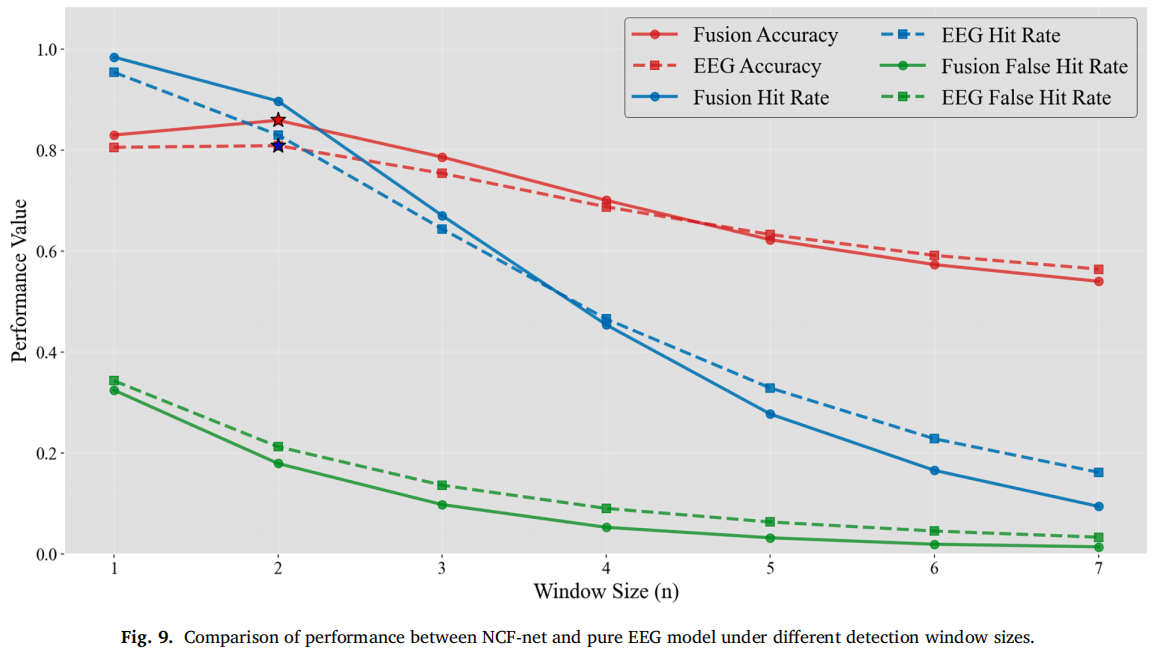
3. NCF-Net 融合优于纯 EEG
在伪在线实验中,NCF-Net 在检测窗口 n=2 时达到最佳,准确率为 0.859±0.025,显著高于纯 EEG 模型的 0.809±0.062。
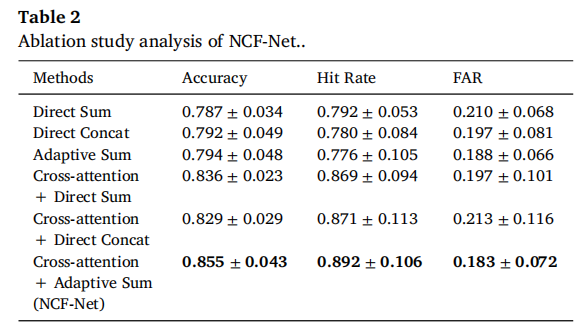
消融实验显示,cross-attention 是性能提升的核心,而 adaptive sum 进一步优化了融合效果。NCF-Net 最终达到 Accuracy 0.855、Hit Rate 0.892、FAR 0.183,优于直接相加、直接拼接、普通自适应相加等策略。
这说明单纯“把 EEG 和图像拼起来”不够,关键在于建立跨模态注意力关系。
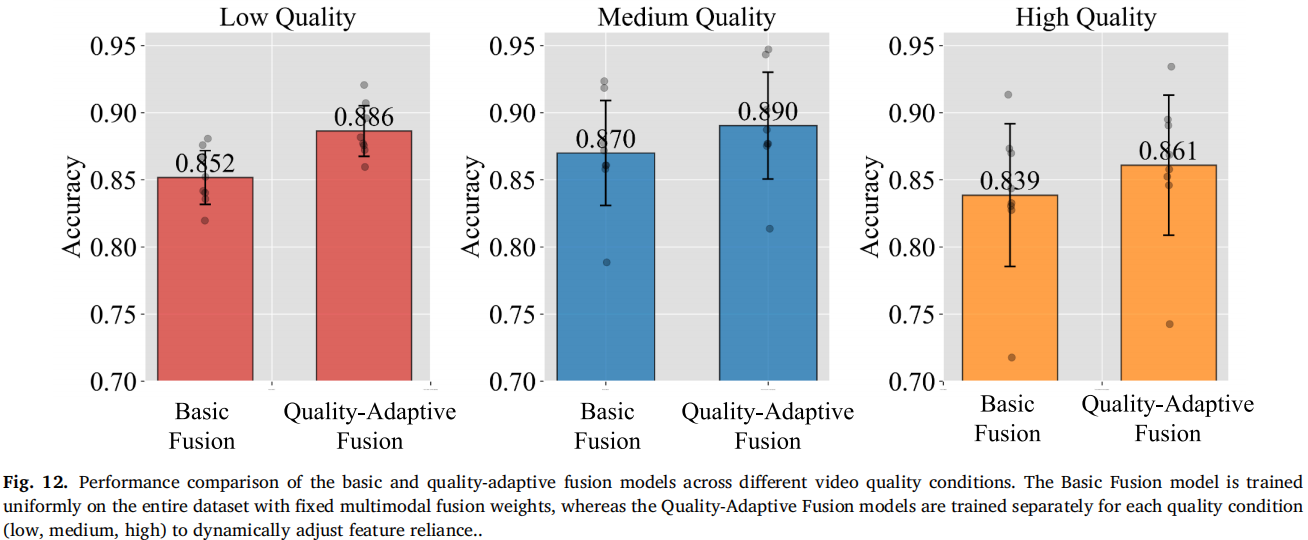
4. 分质量训练优于统一训练
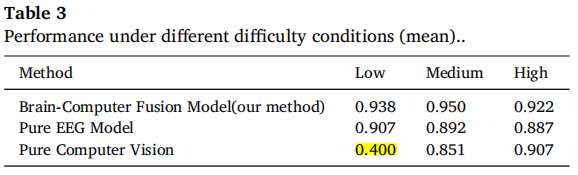
作者比较了统一训练的 Basic Fusion 和按视频质量分别训练的 Quality-Adaptive Fusion。结果显示,按低/中/高质量分别训练模型后,整体效果更好。表 3 中,脑机融合模型在低、中、高质量条件下分别达到 0.938、0.950、0.922;纯 EEG 为 0.907、0.892、0.887;纯视觉为 0.400、0.851、0.907。
这个结果非常关键:
低质量下,纯视觉几乎崩掉,只有 0.400;
但脑机融合仍达到 0.938。
这正好支撑了论文的核心主张:在视觉退化时,人的神经反应和注视信息能补足机器视觉的不足。
5. 在线系统有一定实时性
在线实验中,融合系统平均准确率从纯 EEG 的 0.896 提升到 0.937;加入视频质量评估后的自适应策略达到 0.932,同时减少认知负担,并保持较高命中率。系统平均每个窗口推理时间为 32.81 ms,说明具备持续在线运行的可行性。
五、创新点
第一,把眼动作为 EEG-图像语义对齐的中介。
这比直接融合 EEG 和整帧图像更合理,因为 EEG 反映的是人正在关注的视觉内容。第二,MSST-Net 针对 EEG 的多尺度频率和时空特征建模。
它不是直接套用普通 CNN,而是结合 EEG 的频段特性和空间通道结构设计。第三,提出质量自适应脑机协同策略。
系统不是无条件融合,而是根据视频质量动态决定是否启用脑机融合,这在应用上更接近实际需求。第四,有伪在线和在线验证。
很多 BCI 论文停留在离线分类,这篇至少尝试了接近实时系统的验证。
“眼动对齐 + EEG 解码 + 跨模态注意力 + 视频质量自适应”的整体系统思路



