Introduction Writing of Scientific Papers
Paper 1
题目: Brain-inspired deep learning model for EEG-based low-quality video target detection with phased encoding and aligned fusion
期刊: Expert Systems With Applications
年份: 2025
Introduction思路
Introduction核心逻辑:
低质量视频目标检测很难 → 传统CV和人工方法都有不足 → 人脑在复杂视觉场景中有优势 → EEG/BCI可以把这种脑响应转化为自动检测信号 → 现有EEG方法主要面向图像/RSVP,不适合低质量视频 → 因此需要一种受脑机制启发的分阶段编码与融合模型
第一层:先建立应用背景和问题重要性
文章开头先说 video target detection 在自动驾驶、工业检测、安防、生态监测、灾害响应、无人机等场景中都有重要应用。然后马上收缩到本文关注的问题:很多视频,尤其是 UAV 航拍视频,会受到环境干扰、低分辨率、运动不稳定等影响,导致视频质量低,因此低质量视频中的目标检测成为一个重要问题。
这一段的作用是:
先证明任务有应用价值,再说明“低质量视频”是一个实际且困难的场景。
第二层:指出现有 CV / 人工方法的局限
接下来作者说,UAV 视频目标检测通常依赖 计算机视觉方法或人工检测方法,但仍有两个核心挑战:
第一,航拍视角下目标容易被遮挡、碎片化、小目标化,天气等因素会降低检测精度。
第二,在军事侦察、灾害响应等不确定场景中,目标类别或形态缺乏先验信息,导致深度学习模型在少样本或未知目标条件下效果受限。
这里的逻辑是:
CV 方法强,但依赖清晰视觉证据和充分训练数据;低质量视频中恰恰缺少这些条件。
然后作者又补充人工检测的问题:低质量场景下有些目标肉眼也难以识别,而且人工报告有延迟,不适合实时检测和多任务环境。
所以这一部分把传统方法的不足分成两类:
CV 的问题:泛化弱、少样本弱、受低质量图像影响。
人工的问题:延迟高、负担大、不适合实时和多任务。
第三层:引出人脑优势,再引出 EEG/BCI
在指出 CV 和人工检测不足之后,作者没有直接跳到自己的模型,而是先引入 人脑视觉认知能力。
作者强调,人脑在低质量视频目标检测中具有推理和适应能力。比如,人脑可以利用背景上下文和经验推断模糊或遮挡目标,也具备少样本识别能力。
但是,如果只依赖人来手动报告,又会带来延迟和多任务场景下的不便。因此作者进一步引出 BCI:
既然人脑能感知复杂目标,但人工报告慢,那么可以用 EEG 直接捕获目标相关脑响应,让系统自动解码。
这一层是这篇 Introduction 很关键的转折:
它不是简单说“EEG 很有用”,而是先证明人脑机制能补足CV的不足,再说明BCI/EEG是把人脑优势引入自动检测系统的技术路径。
第四层:综述 EEG 目标检测研究,并指出不足
接下来作者进入相关工作综述。
他先讲传统 EEG 目标检测主要集中在 RSVP 图像目标检测,利用 ERP 识别目标。然后列举了 HDCA、xDAWN、Riemannian 方法等传统 EEG 解码算法。之后再过渡到深度学习方法,包括 EEGNet、PLNet、TFF-Former、pyramid squeeze attention 等。
但是作者马上指出关键问题:
这些 EEG-based target detection 方法大多面向图像,而不是视频;将它们直接迁移到低质量视频目标检测中仍然困难。
这一段的作用是建立研究空白:
不是说“EEG 目标检测没人做”,而是说:
做过,但大多是图像 RSVP;做过深度学习,但不针对低质量视频;所以本文的问题仍然没有被很好解决。
第五层:进一步缩小到“低质量视频 EEG 解码”的算法缺口
作者又提到他们之前的工作用 FRP 代替 ERP,解决了目标出现时间和被试识别时间不同步的问题。也就是说,之前已经在范式和信号对齐上做了一步。
但作者指出,虽然 FRP 可以部分缓解异步问题,如何基于提取出的 FRP 片段设计更有效的分类算法,仍然有研究空间。
这一步非常重要,因为它把 gap 从“大领域缺口”进一步缩小为“本文具体要解决的算法问题”:
不是重新设计整个实验范式,而是在已有低质量视频 FRP 信号基础上,设计更适合该脑响应机制的深度学习模型。
第六层:引出 brain-inspired model,并说明现有脑启发方法不足
然后作者开始引入 brain-inspired algorithm。他综述了 Type-2 fuzzy logic、SNN、HTM、Hebbian learning 等脑启发 EEG 方法。之后转到视觉 BCI 中“分阶段处理”的研究,并提到 SAST-GCN 这类将 EEG 分为多个阶段进行处理的方法。
但是作者指出,已有方法主要针对高质量视频,不包含低质量视频中更复杂的脑过程,比如 spatial tracking 和 long-term attention,因此不适合本文任务。
这一段的逻辑是:
已有脑启发方法提供了方向,但还没有针对低质量视频目标检测的真实脑机制来设计模型。
第七层:提出本文的“脑机制依据”
这是 Introduction 里最核心的部分。
作者提出,低质量视频目标检测不同于 RSVP 图像任务或高质量视频任务,它涉及更复杂的多阶段脑机制。
作者把该过程分为三个阶段:
Early phase:目标出现后的惊奇反应、识别和评估,对应 P3a/P3b/P300,主要涉及 PPC。
Later phase:目标被发现后,运动目标诱发空间跟踪反应,主要涉及 V2、V3、MT 等视觉运动相关区域。
Full phase:整个 0–1 s 过程中持续注意和认知加工,主要涉及 PFC。
Fig. 1 也正是为这一逻辑服务的:它把 Recognition、Spatial Tracking 和 Attention 三个阶段画出来,使后续模型的“分阶段编码”和“对齐融合”变得合理。
这一部分的作用是把方法创新建立在神经机制上:
模型为什么要分阶段?因为脑响应本身是分阶段的。
为什么要对齐融合?因为除了早期识别和后期跟踪,还有贯穿全程的持续注意。
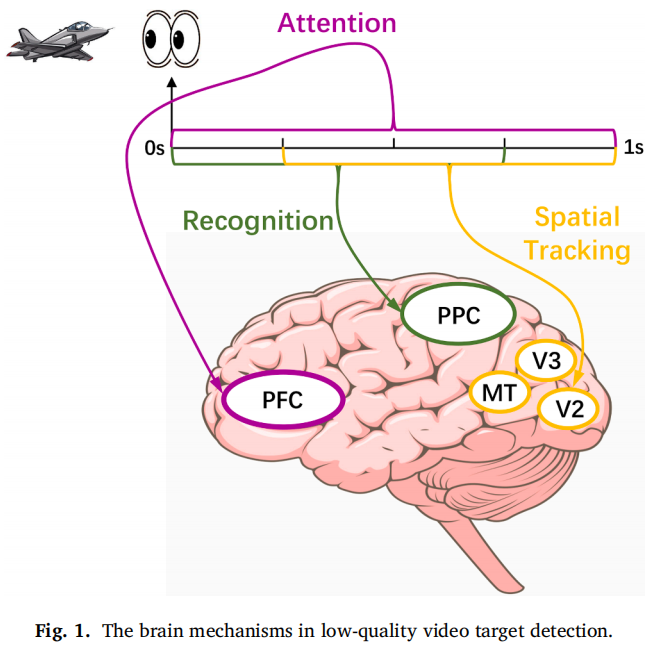
第八层:自然引出本文方法
在完成脑机制铺垫后,作者最后提出模型:针对 early phase 和 later phase,将 1 秒 EEG 片段分成两个重叠阶段:前 0.75 s 和后 0.75 s;每个阶段通过 Phased Encoder 提取时空特征;然后为了捕获 full-phase attention,对两个阶段特征进行对齐、时间匹配和拼接,再通过时间网络提取全阶段特征用于分类。
所以方法不是突然出现的,而是从前面的脑机制自然推出来的:
Recognition → 前阶段编码
Spatial tracking → 后阶段编码
Sustained attention → 跨阶段对齐融合 + 全局时间特征提取
这就是这篇 Introduction 最值得学习的地方:每个模型模块都能在前文找到神经机制依据。
最后总结贡献
最后作者总结了三类贡献:
第一,提出一种脑启发的分阶段编码与特征对齐融合模型,用于 EEG-based low-quality video target detection。
第二,通过时域和频域 EEG 分析,证明脑响应具有 early recognition、later spatial tracking 和 full-phase attention 三个阶段,并与模型结构对应。
第三,在有无 ICA、认知分心、多种条件下进行实验,证明模型相比 baseline 具有更好的精度和鲁棒性。
它的贡献写法不是单纯罗列“我们提出了一个模型”,而是围绕一个主线展开:
脑机制发现 → 模型设计 → 多条件验证。
整体逻辑链
应用价值
低质量 UAV 视频目标检测很重要。
⬇️
现实困难
低质量、遮挡、小目标、不确定场景、少样本导致 CV 方法受限。
⬇️
人脑优势
人脑可以利用经验、上下文和少样本能力识别复杂目标。
⬇️
人工检测不足
人虽然强,但手动报告慢,不适合实时和多任务。
⬇️
BCI/EEG 作为桥梁
EEG 可以捕获无意识目标响应,实现自动化目标检测。
⬇️
已有 EEG 方法不足
多数方法面向 RSVP 图像,不适合低质量视频。
⬇️
已有脑启发方法不足
已有分阶段 EEG 方法主要针对高质量视频,未考虑低质量视频中的空间跟踪和持续注意。
⬇️
本文脑机制假设
低质量视频目标检测包含 early recognition、later spatial tracking、full-phase attention 三个阶段。
⬇️
本文方法
提出 phased encoding + aligned fusion 的脑启发深度学习模型。


