No.6
标签:三通道跨被试注意力机制情感识别
前言
《Hybrid Source Selection Fusion Domain-invariant Attention for Cross-subject Emotion Recognition》
期刊:IEEE Transactions on Affective Computing
年份:2025
分区:Q1,一区Top;IF:9.8
作者:Gang Luo, Yao Zou, Shuaiyi Xu, Wei Zhang, Lixian Zhu, Fuze Tian, Na Chu, Kun Qian, Senior Member, IEEE, Xiaowei Li, Member, IEEE, Jingxin Liu, Shuting Sun, Bin Hu, Fellow, IEEE
主要单位:School of Medical Technology, Beijing Institute of Technology
- 解决跨被试EEG情绪识别问题(Cross-subject Emotion Recognition)
核心困难:
- EEG 非平稳 + 个体差异,所以:训练好的模型 换一个人就失效
- 传统方法的问题:
很多方法直接:所有被试 → 统一 source domain
问题:有些被试和目标被试差异很大,
会导致 负迁移(negative transfer)- 传统方法的第二个问题:特征重要性
很多方法:domain-invariant feature
但:所有feature权重一样
实际上:不同 EEG channel / band 对情绪贡献不同。
一、研究背景与动机
1. 研究意义
- 情绪识别在心理健康监测、抑郁、自闭症等精神疾病辅助诊断中具有重要应用价值。
- 脑电图(EEG)因其便携性和高时间分辨率,成为情绪识别的重要工具。
2. 问题挑战
- 个体差异和EEG信号的非平稳性使得跨被试情绪识别极具挑战。
- 现有方法通常将所有被试的数据视为一个整体源域,可能导致:
- 负迁移(引入不相关信息)
- 忽略共性情绪特征中的重要信息
二、提出的方法:HSSFDA
1. 核心思想
整体 pipeline:
Source domains ➡️ Hybrid Source Selection ➡️ Feature Extraction ➡️ Domain Adaptation ➡️ Attention ➡️ Classification
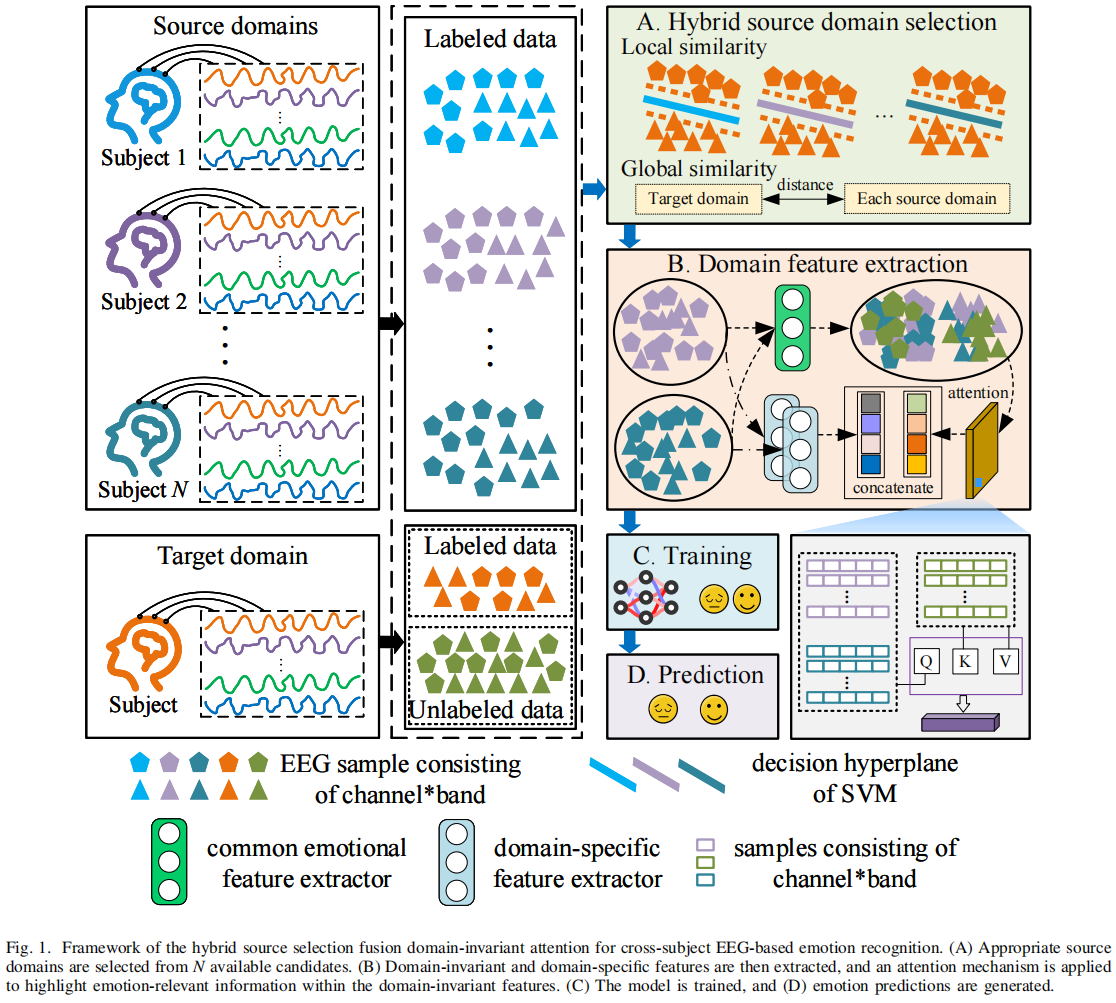
更细拆:
- Step1 选 source domain
利用:local similarity+global similarity
局部相似性:使用SVM分类器在少量有标签目标域数据上评估源域性能。
全局相似性:使用欧氏距离评估源域与目标域的整体分布差异。
综合排序:将两种相似性归一化后加权,选出最相关的 M 个源域
- Step2 特征提取
提取两类特征:
1️⃣ Domain-invariant feature 跨被试共享情绪信息
2️⃣ Domain-specific feature 个体差异
使用共享子网络提取域不变特征。
引入多头注意力机制,聚焦于情绪相关的重要特征,提升判别能力。
- Step3 Attention
在 invariant feature 上做:multi-head attention,突出关键 EEG channel - Step4 域适配 用:MMD loss,对齐 source / target
- Step5 分类:softmax
提取域特定特征,并使用最大均值差异(MMD) 对齐源域与目标域分布。
最终将域不变与域特定特征融合,进行分类。
三、实验设计与结果
1. 数据集
- 公共数据集:SEED、SEED_IV、DREAMER、DEAP
- 自采集数据集:12名健康被试,使用三通道便携EEG设备采集
2. 实验设置
- 使用留一被试交叉验证(LOSO-CV)
- 特征:差分熵(DE) 在五个频带(delta, theta, alpha, beta, gamma)上提取
3. 主要实验结果
性能对比
HSSFDA在所有数据集上均优于现有方法,如TCA、DAN、DGCNN、BiDANN等。
在SEED上提升约1.26%,在SEED_IV上提升约1.89%,在DREAMER和DEAP上也表现优异。消融实验
移除注意力模块或距离评估模块后,性能下降,验证了各模块的有效性。混淆矩阵分析
SEED:对正向情绪识别最敏感,负向情绪易混淆为中性。
SEED_IV:中性和悲伤情绪更易识别,快乐最难。
DREAMER/DEAP:高效价/高唤醒度情绪更易识别。特征可视化(t-SNE)
HSSFDA能有效将同类情绪样本聚集,异类情绪样本分离,说明其学习到的特征具有良好判别性。通道权重可视化
模型关注额叶、颞叶、顶叶等与情绪处理相关脑区,符合神经科学认知。自采集数据集
在便携三通道设备上也取得了58.99% 的准确率,验证了方法的实用性。

四、核心创新点
1. Hybrid Source Selection
local + global similarity
用于避免负迁移。
2. Domain-invariant attention
强调:
跨被试共享情绪特征。



