No.7
标签:腰椎几何重构深度学习框架(磁共振图像)
前言
《Attention-Based Shape-Deformation Networks for Artifact-Free Geometry Reconstruction of Lumbar Spine From MR Images》
期刊:IEEE TRANSACTIONS ON MEDICAL IMAGING
年份:2025
分区:Q1,一区Top;IF:9.8
作者:Linchen Qian, Jiasong Chen, Linhai Ma, Timur Urakov, Weiyong Gu, and Liang Liang
主要单位:University of Miami
- 传统方法:MRI → segmentation → mask → mesh → 测量
- 问题:segmentation mask 有伪影(断裂 / 多余区域 / 错标签),无法稳定转换为结构化 mesh
👉 导致医学参数测量不可靠 - 论文提出:❌ 不做 segmentation,✅ 直接从图像 → deform template mesh
👉 这是范式转变(segmentation → geometry reconstruction)
一、研究背景与问题定位
1. 临床意义
- 腰椎间盘退变是导致腰痛的重要原因,MRI 是评估其形态和退变程度的关键手段。
2. 现有方法的局限
- 图像分割方法(如 UNet、DGMSNet、SpineParseNet)常产生伪影(如多余区域、标签混淆、断裂区域),无法直接用于结构化几何重建。
- 分割后处理为网格的过程复杂且易错。
- 缺乏跨患者的网格对应关系,无法在统一解剖结构上定义医学参数。
二、方法主线
设计思路
论文核心其实是一个统一思想:
🧠 “用 attention 来预测 template mesh 每个点的位移”
🔵 模型1:UNet-DeformSA
1️⃣ 出发点(很自然的 baseline + 改进)
从已有方法演化:
UNet-GCN(已有工作)
↓ 不够好(只能局部邻域)
UNet + Attention(作者改进)
👉 问题在这里:GCN➡️只能邻域传播(局部);CNN➡️无法建模 long-range
👉 作者结论:椎体结构是全局耦合的形变问题
2️⃣ 核心设计
UNet backbone(提图像特征)
3个 deformation stage(逐步变形)
每个 stage:image sampling;shape self-attention
3️⃣ 本质创新
👉 Shape Self-Attention(SSA)
token = mesh点
attention 在“点与点之间”
👉 学到的是:“哪些点一起动?”
4️⃣ 一句话总结
✅ UNet-DeformSA = CNN特征 + 点级自注意力形变
🔴 模型2:TransDeformer(真正的主角)
这是论文的核心创新模型
1️⃣ 为什么要提出第二个模型?
作者发现:UNet still 限制了表达能力
👉 所以直接:❌ 去掉UNet;✅ 全 attention 架构
2️⃣ 三大模块
🧩 (1) Image Feature Extractor
CNN + Image Self-Attention (ISA) 👉 把图像变成 token
🧩 (2) Shape Deformation Block
包含两个 attention:
🔹 Shape Self-Attention (SSA) 👉 点与点之间关系
🔹 Shape-to-Image Attention (S2IA) 👉 点 ↔ 图像 👉 这是关键:“这个点应该看图像哪里?”
🧩 (3) Shape Refinement Block 👉 最后精修
3️⃣ 真正创新点
⭐ 创新1:Shape token + Image token 交互
传统:图像 → feature → output
这里:
图像 token
形状 token
双向 attention
👉 本质是:geometry = token interaction problem
⭐ 创新2:新的 attention公式
👉 引入:relative position embedding,位置差 (pi - pj)
👉 实际意义:attention 不只是 feature 相似,还编码 空间关系
⭐ 创新3:显式预测“位移”
不是 segmentation
而是:Δx, Δy for each point
4️⃣ 一句话总结
✅ TransDeformer = Transformer版的 mesh deformation network(跨模态 attention)
🔥 两个模型本质区别
UNet-DeformSA 👉 CNN + shape attention
TransDeformer 👉 全 attention(image↔shape)
两种网络具体结构:
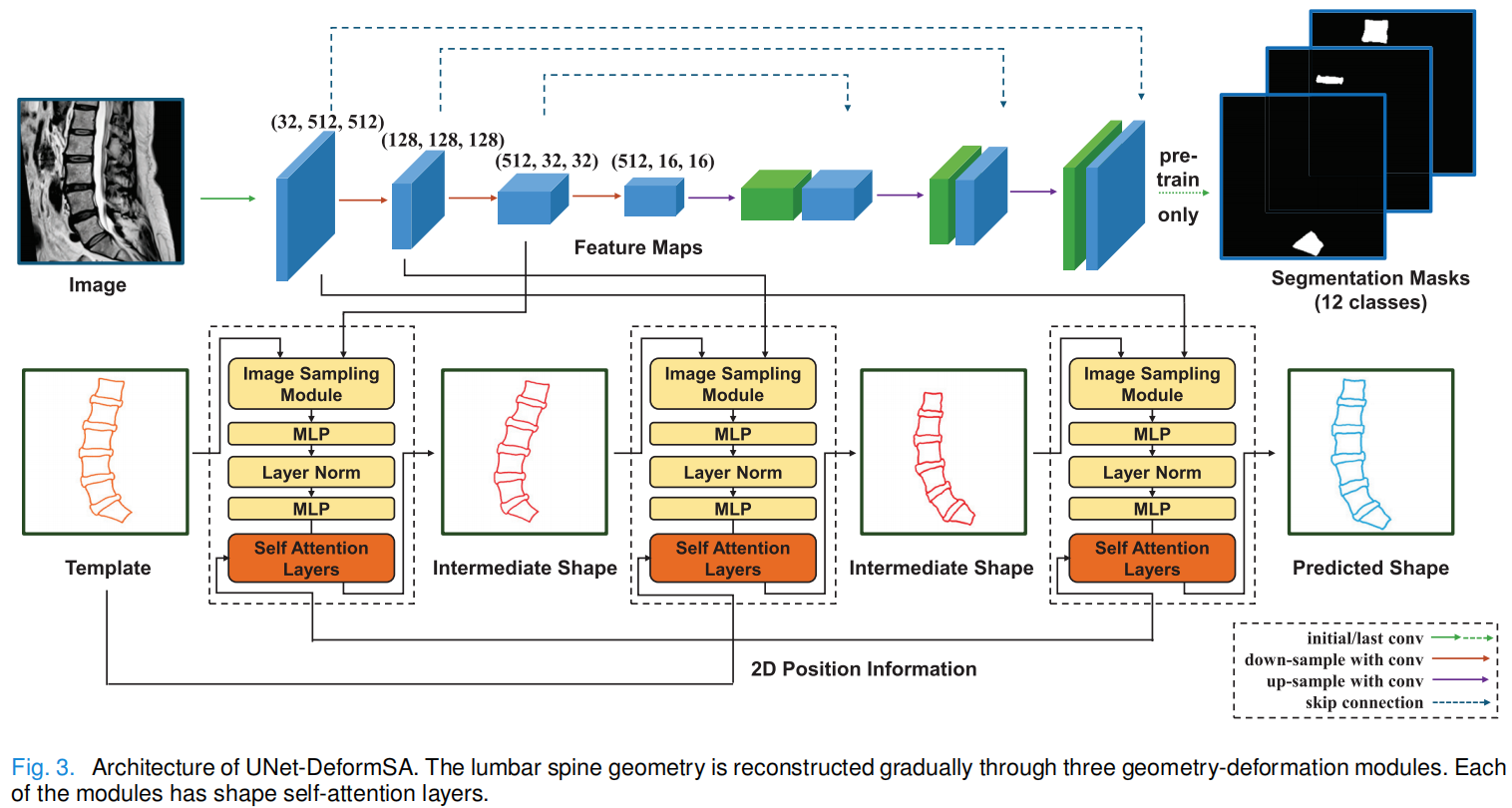
1.UNet-DeformSA
- 基于 UNet 骨干网络 + 形状自注意力模块。
- 通过三个几何变形模块逐步变形模板。
- 依赖 UNet 提取图像特征。
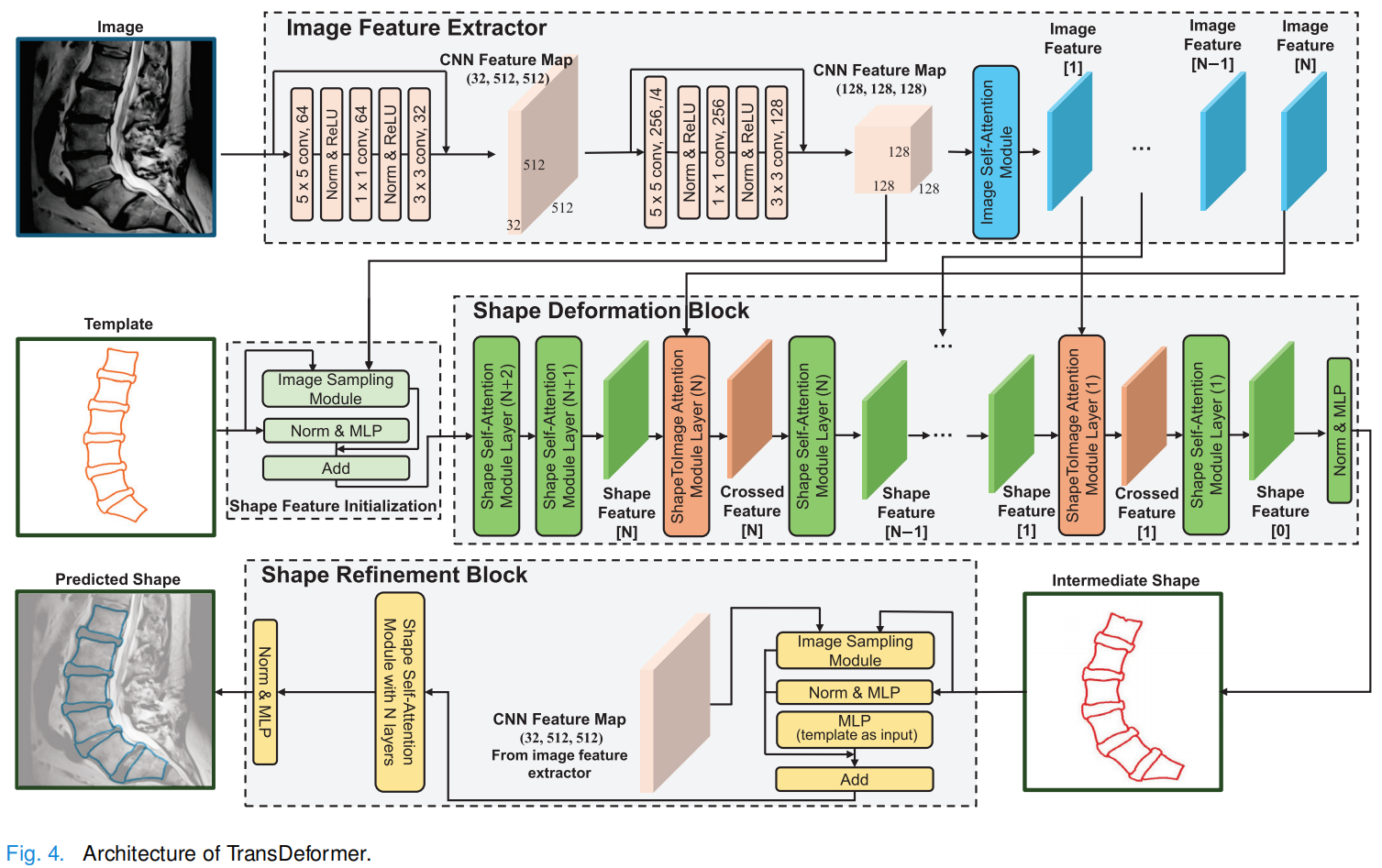
2.TransDeformer(核心创新)
- 无需 UNet 骨干,完全基于注意力机制。
- 包含三个关键模块:
- 图像自注意力:提取图像特征,采用分块处理。
- 形状自注意力:建模模板点之间的依赖关系。
- 形状-图像交叉注意力:建立模板点与图像块之间的长程依赖。
- 使用新的注意力公式,引入相对位置编码,增强几何变形能力。
3.误差估计模型
- 基于 TransDeformer 修改,输出每个点的预测误差,用于质量控制和样本排序。
三阶段训练策略
- Mode 1:只学 centroid 👉 粗定位
- Mode 2:学完整 shape 👉 精细
- Mode 3:扰动 template 👉 提升鲁棒性
📌 关键思想:coarse → fine + robustness
三、实验结果
多个表格的实验结果,在两个公开数据集上所验证的
- Table 1
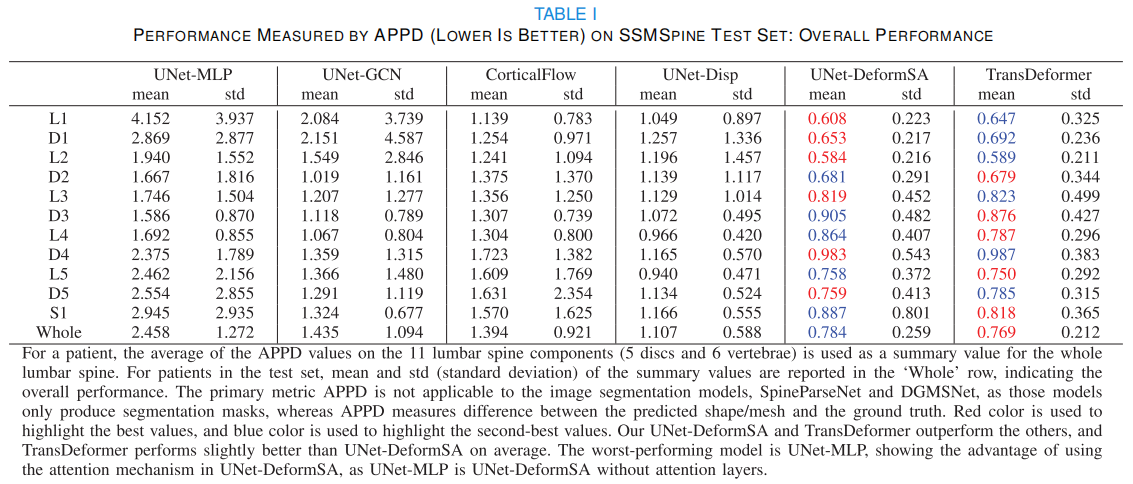
结论:
- TransDeformer最好 ✅ attention > GCN > CNN
- Attention真的有效
- TransDeformer略优于UNet-DeformSA
- Table 2
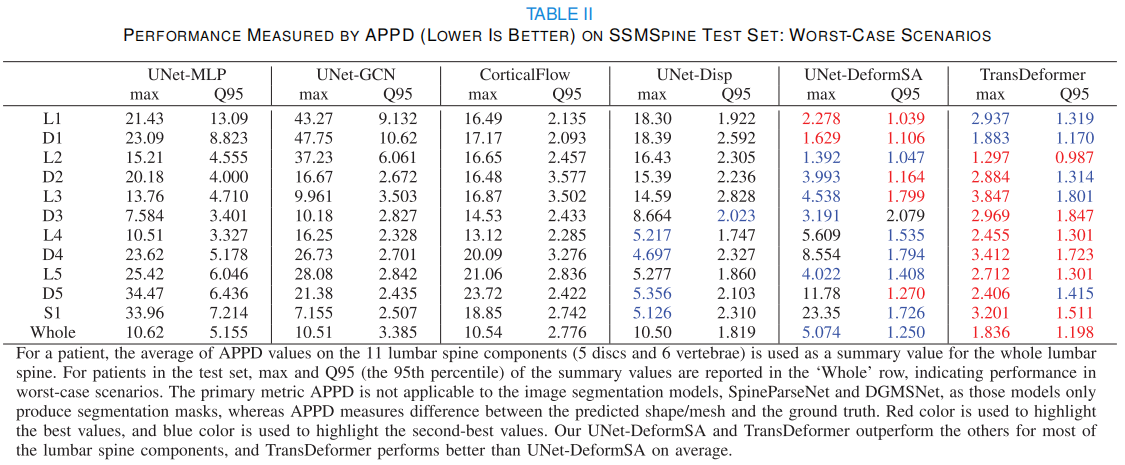
结论:
- 模型不仅平均好,极端情况也更稳
四、贡献
1️⃣ 方法层面
第一次把 attention用于模板形变
提出 shape-token + image-token 交互框架
2️⃣ 表示层面
segmentation → mesh(范式改变)



