No.8
标签:多类别目标RSVP-BCI、EEG与眼动融合、信息融合、脑机接口
前言
《Exploring EEG and eye movement fusion for multi-class target RSVP-BCI》
期刊:Information Fusion
年份:2025
分区:Q1,一区Top;IF:15.5
作者:Xujin Li, Wei Wei, Kun Zhao, Jiayu Mao, Yizhuo Lu, Shuang Qiu, Huiguang He
主要单位:Institute of Automation, Chinese Academy of Sciences
❗从单类 → 多类 RSVP(关键转变)
传统 RSVP:target vs non-target(2类)
现在:target-1 vs target-2 vs non-target(3类)👉 难点:
🔥 难点1:EEG P300高度相似
论文明确说:不同 target 类别的 ERP latency 类似,但 amplitude 有差异
👉 本质:❌ EEG 很难区分类别;✅ 只能判断“是不是 target”
🔥 难点2:现有方法只用 EEG
👉 问题:EEG:认知信号(慢);EM(眼动):行为信号(快)
👉 但以前:❌ 没有 multi-class + EEG+EM dataset;❌ 没有针对 multi-class 的融合方法✅ 作者核心思想:用 EM 补 EEG 的类别区分能力
一、研究背景与问题定位
1. 背景
- 传统RSVP-BCI系统只能检测单类别目标(二分类:目标 vs. 非目标),难以应对需要识别多种目标的复杂任务。
- 多类别目标RSVP任务要求系统同时检测目标是否存在,并区分其具体类别(如:民用飞机 vs. 军用飞机)。
2. 挑战
- 不同目标类别诱发的事件相关电位(ERP)相似度高,难以区分;
- 现有研究多依赖单一EEG模态,忽略了眼动信号中蕴含的丰富认知信息;
- 缺乏多模态多类别RSVP数据集。
二、模型架构
设计思路
MTREE-Net = 两模态特征提取 + 跨模态增强 + 理论引导融合 + 层级蒸馏
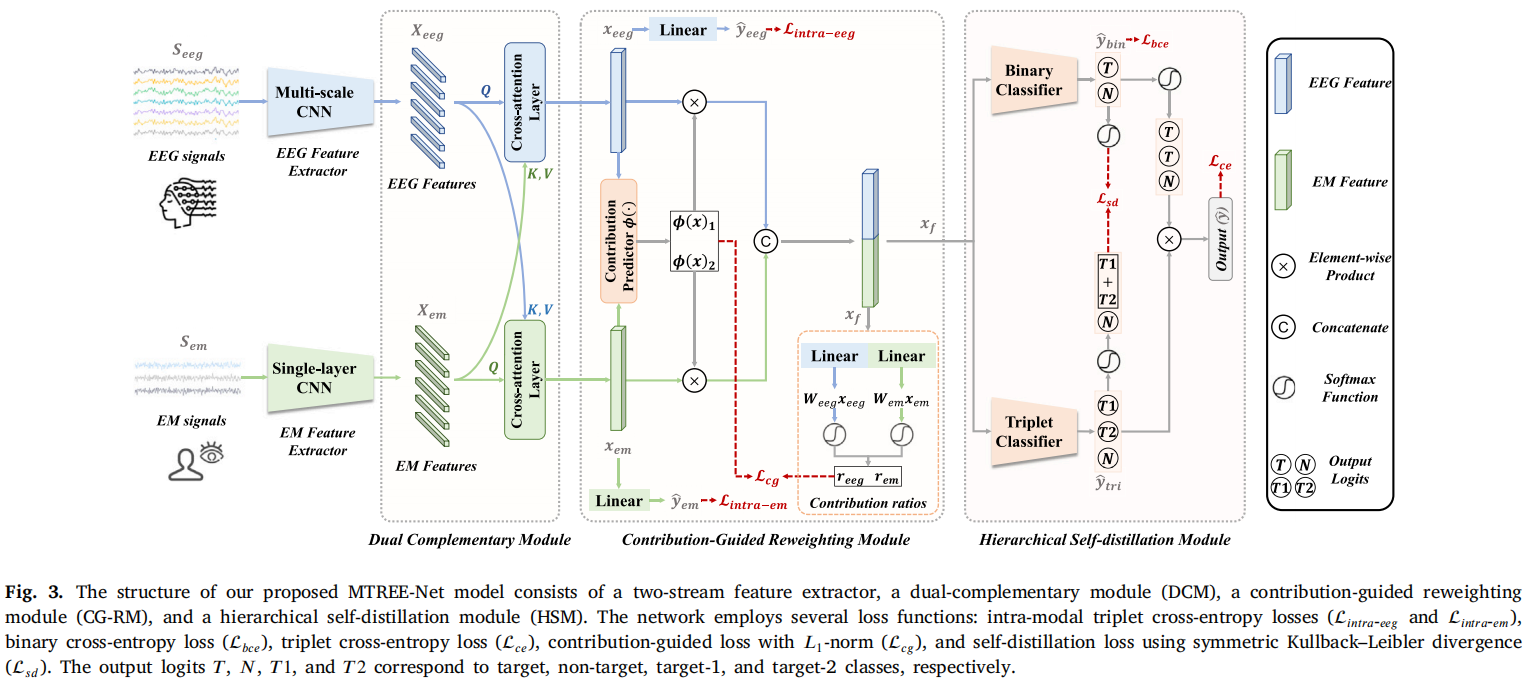
🔵 1. Feature Extractor(不是重点,但有设计)
EEG:Multi-scale CNN(多尺度时间建模)
👉 抓:P300(200–600ms);不同频段
EM:单层卷积
👉 原因:EM 比 EEG 简单(论文明确说)
🔴 2. DCM(Dual-Complementary Module)⭐关键1
❗问题:模态不平衡
论文说:EEG 更强 → EM 学不好
✅ 解决:Cross-Attention
👉 双向信息流:
EEG → EM 教 EM
EM → EEG 补 EEG
⭐ 本质一句话:让两个模态互相“教对方”
🔴 3. CG-RM(Contribution-Guided Reweighting)⭐最核心
❗问题:传统 fusion 不合理
传统:feature concat → classifier
👉 问题:❌ 默认 EEG = EM 权重相同
✅ 作者关键 insight
👉 从 logits 出发:
𝑓(𝑥)=𝑓(𝑥𝑒𝑒𝑔)+𝑓(𝑥𝑒𝑚)
🔥 关键解释
👉 每个模态对分类都有“贡献”
👉 如果:EEG logits 高 → EEG 更重要;EM logits 高 → EM 更重要
⭐ 定义贡献𝑐𝑒𝑒𝑔,𝑐𝑒𝑚 → 再变成比例:𝑟𝑒𝑒𝑔,𝑟𝑒𝑚
⭐ 然后训练一个网络:𝜙(𝑥𝑒𝑒𝑔,𝑥𝑒𝑚)→权重;目标:让预测权重 ≈ 理论贡献
🔥 核心创新 👉 用 理论贡献监督 fusion 权重
不是:loss 自动学;而是:理论指导学习
🔴 4. HSM(Hierarchical Self-Distillation)⭐关键2
❗问题:multi-class 难:
- target1 vs target2 很难
- 但 target vs non-target 很容易
✅ 思路
分两层:
Level 1:binary(easy)
Level 2:3-class(hard)
🔥 做法
Step1:训练两个分类器
- binary classifier
- triplet classifier
Step2:蒸馏
让:𝑡𝑟𝑖𝑝𝑙𝑒𝑡→𝑏𝑖𝑛𝑎𝑟𝑦保持一致
Step3:推理时
𝑦=𝑏𝑖𝑛𝑎𝑟𝑦×𝑡𝑟𝑖𝑝𝑙𝑒𝑡
⭐ 本质:用 easy task 指导 hard task
三、结果分析
表4 模型性能对比
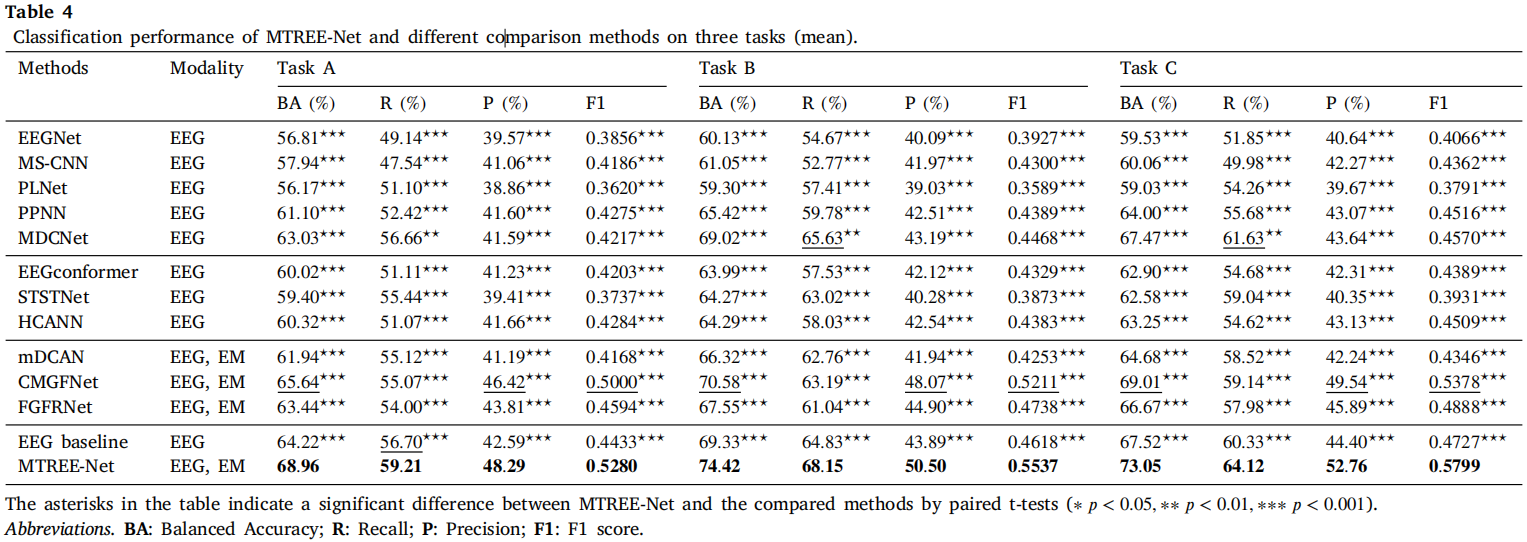
- MTREE-Net在所有任务和指标上显著优于所有对比方法(p < 0.001);
- 比最优EEG-only方法MDCNet在BA上提升约5-7%;
- 比最优融合方法CMGFNet在BA上提升约3-4%。
表5 消融实验结果
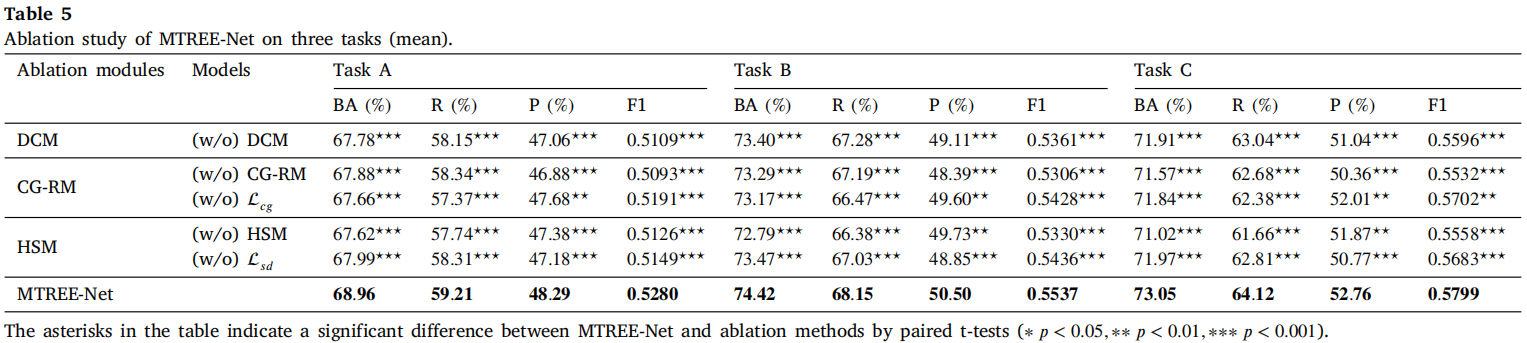
- 移除DCM、CG-RM、HSM均导致性能显著下降;
- 移除贡献引导损失(L_cg)或自蒸馏损失(L_sd)也会显著降低BA。
表6 多模态 vs. 单模态

- 融合模型BA显著高于单一EEG或眼动模型;
- DCM进一步提升融合效果。
表7 眼动成分分析
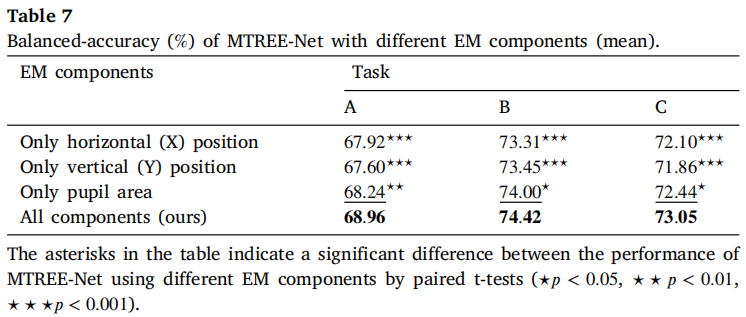
- 瞳孔面积贡献最大,水平位置次之,垂直位置最弱;
- 使用所有眼动成分效果最佳。
表8 互补方向分析
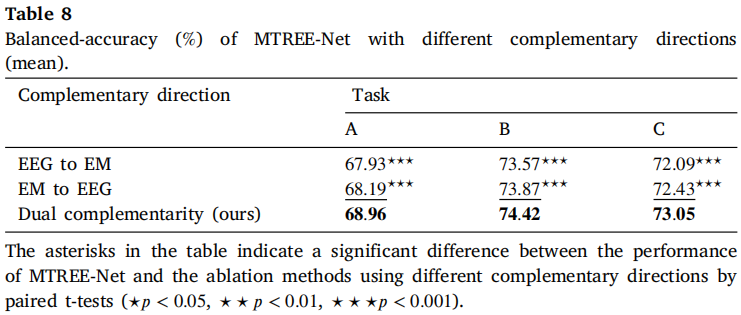
- 双向互补(DCM)优于单向增强(EEG→EM 或 EM→EEG);
- EM→EEG略优于EEG→EM,说明增强强模态更有效。
图7 EEG时空差异
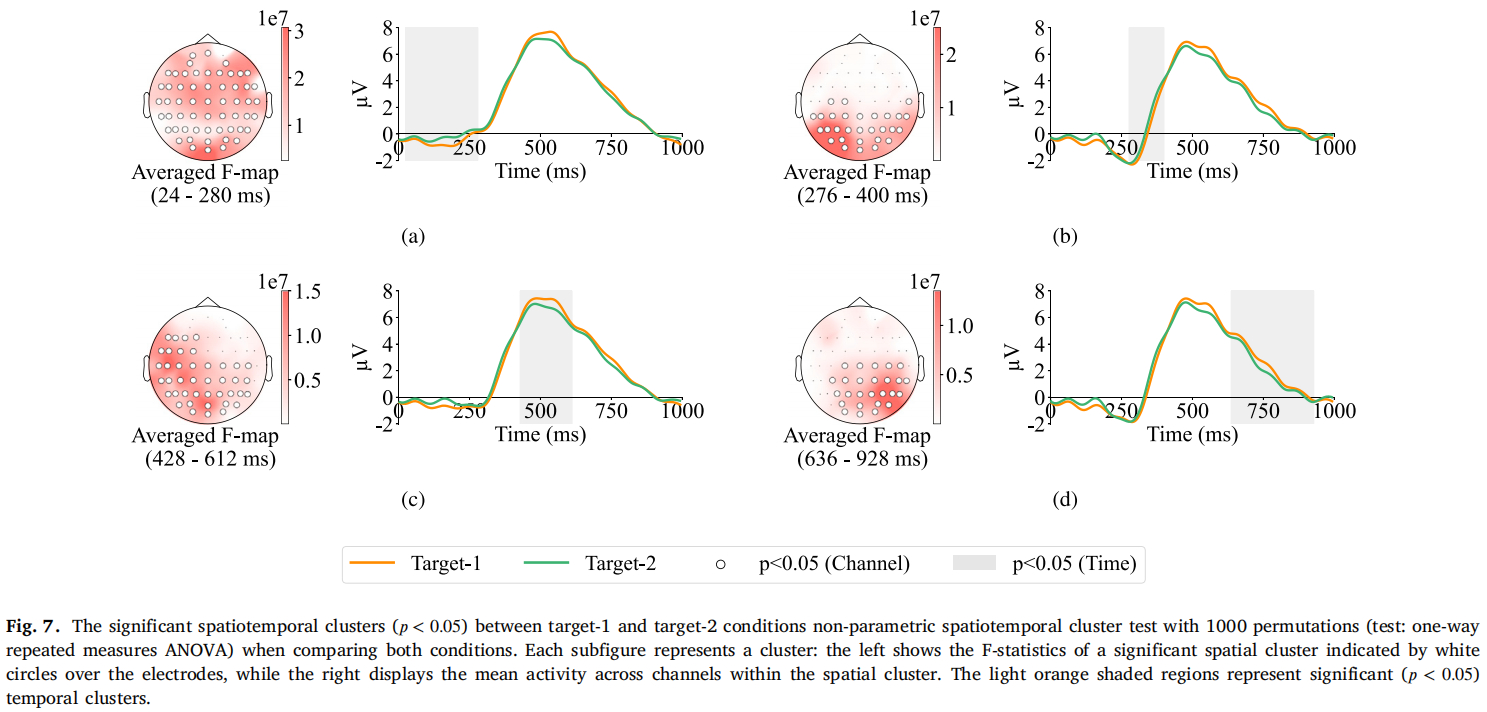
- 目标-1与目标-2在N200和P300时段(200–600ms)存在显著差异;
- 差异集中在顶叶和枕叶区域。
图8 眼动差异
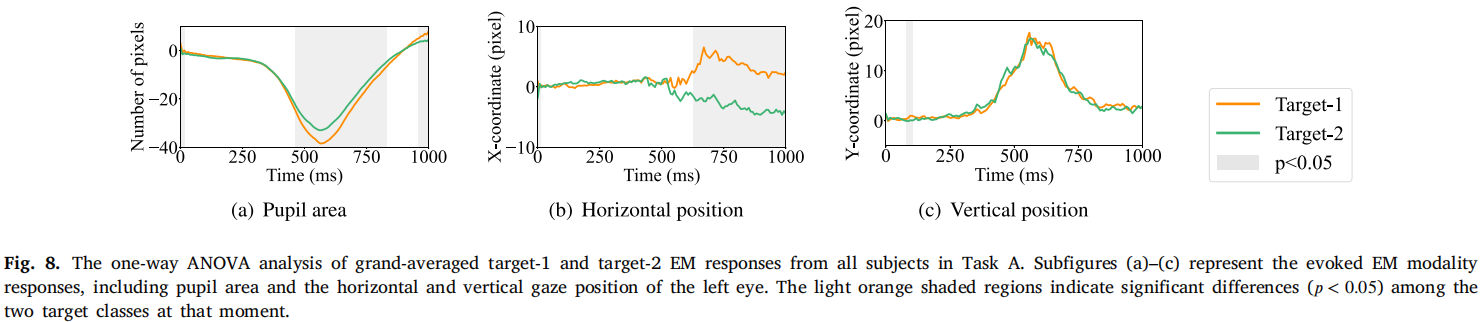
- 瞳孔面积和水平位置在目标类别间存在显著差异;
- 垂直位置差异不显著。
图6 t-SNE可视化
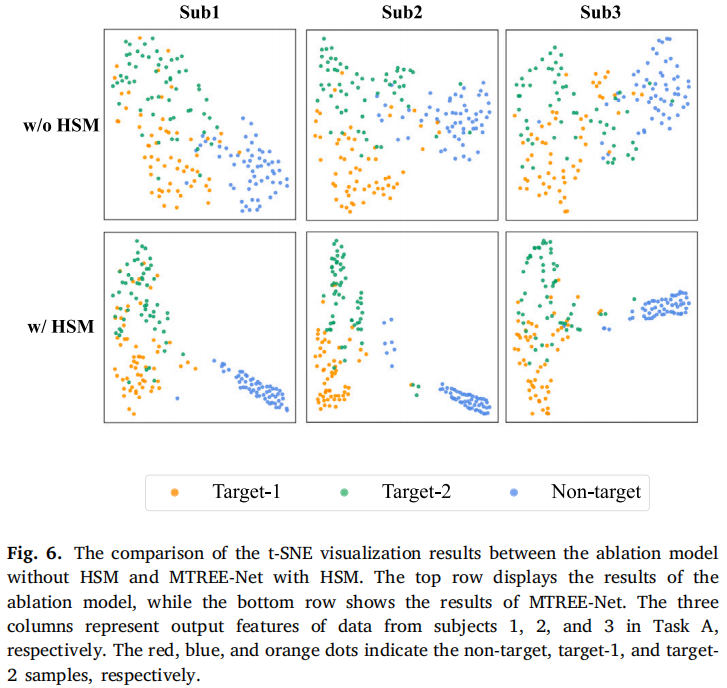
- HSM显著减少了目标与非目标特征的重叠;
- 特征聚类更紧凑,类别可分性更强。
图9 显著性图分析
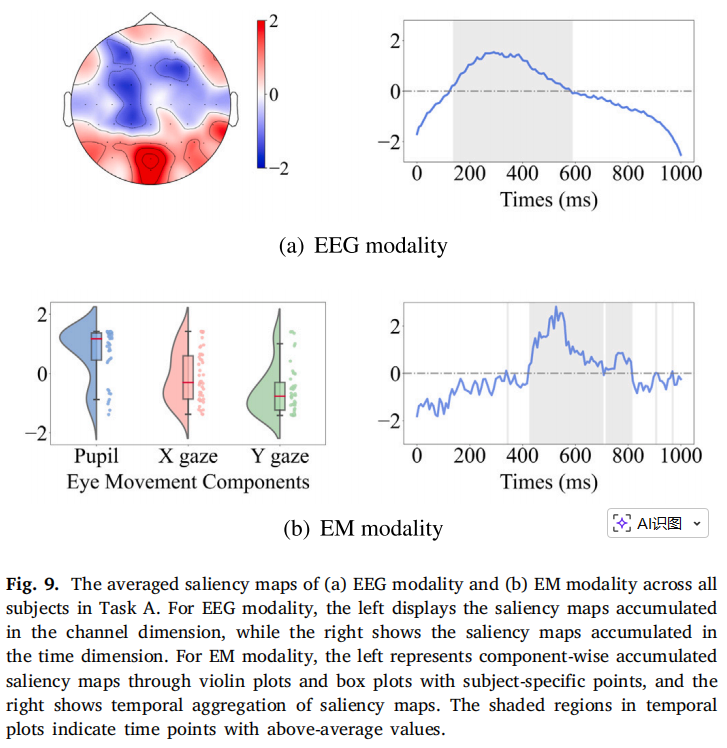
- EEG:模型关注顶枕区、N200/P300时段;
- 眼动:模型关注瞳孔面积和水平位置,时段为437–812ms。
图10 超参数敏感性分析

- 注意力头数(h):h=2 最佳,过大导致过拟合;
- 模态内损失系数(λ):λ=0.2 最佳,过大干扰多模态优化。
四、总结
这篇论文在多类别RSVP-BCI任务中首次系统融合了EEG与眼动信号,提出了MTREE-Net,通过双互补增强、贡献引导融合、分层自蒸馏三大创新,显著提升了解码性能。数据集与代码开源,为后续研究提供了坚实基础。该工作为复杂视觉目标识别BCI系统的发展提供了新范式。



