No.11
标签:MoE 专家机制处理不同传感器组合,让 LLM 输出故障诊断结果和文字解释
前言
《A MoE-LLM-based multisensor flexible fusion fault diagnosis method for rotating machinery》
期刊:Advanced Engineering Informatics
年份:2026
分区:Q1,一区Top;IF:9.9
作者:Tantao Lin, Zhijun Ren, Kai Huang, Hamid Reza Karimi, Yongsheng Zhu, Ke Feng, Jun Hong
主要单位:Xi’an Jiaotong University
- ❗从单类 → 多类 RSVP(关键转变)
传统 RSVP:target vs non-target(2类)
现在:target-1 vs target-2 vs non-target(3类)
一、研究背景与问题定位
1. 背景
- 传统 CNN、RNN、Transformer 故障诊断方法可以做特征提取和分类,但通常是固定输入、固定结构、固定传感器组合。比如模型训练时用“振动+电流”,测试时缺了电流,模型就不一定能用。
- 现有故障诊断多数只能处理单一信号,不能灵活融合多传感器,也难以应对传感器缺失或输入组合变化。
- 为什么用大模型?
第一,LLM 有统一的 token/embedding 表示空间,可以把不同模态的信息映射到同一个空间中。
第二,LLM 有较强上下文建模能力,可以把 **“信号特征 + 文本提示 + 故障知识”**一起处理。
第三,LLM 可以输出自然语言诊断结果,而不是只输出类别编号。论文明确指出,现有 LLM-based fault diagnosis 主要有两类:一种是把信号转成文本,另一种是把信号转成 embedding 输入 LLM;前者容易丢失原始信号结构,后者更适合保留信号信息。
二、整体结构
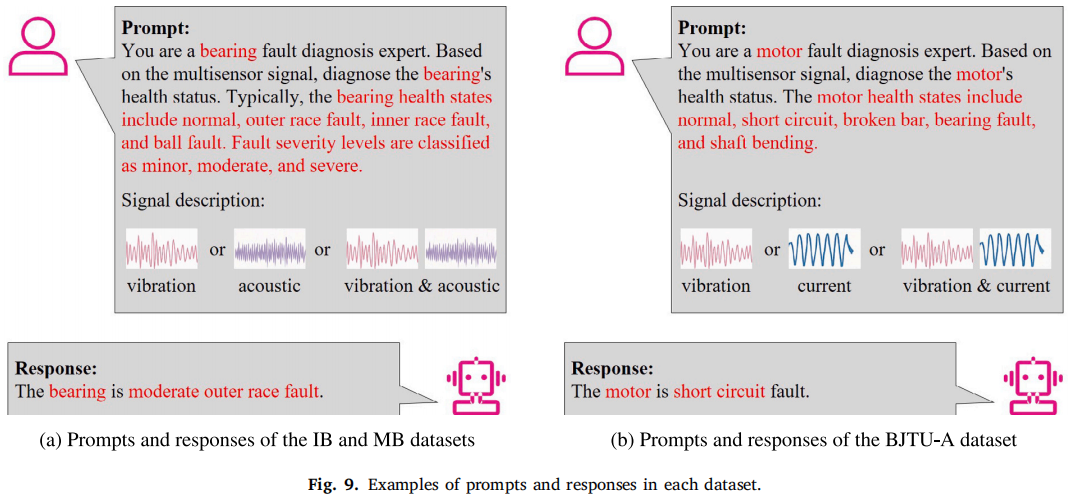
多传感器信号 + prompt
↓
Multisensor Embedding Layer
↓
MoE-LLM
↓
故障诊断结果 + 文本解释
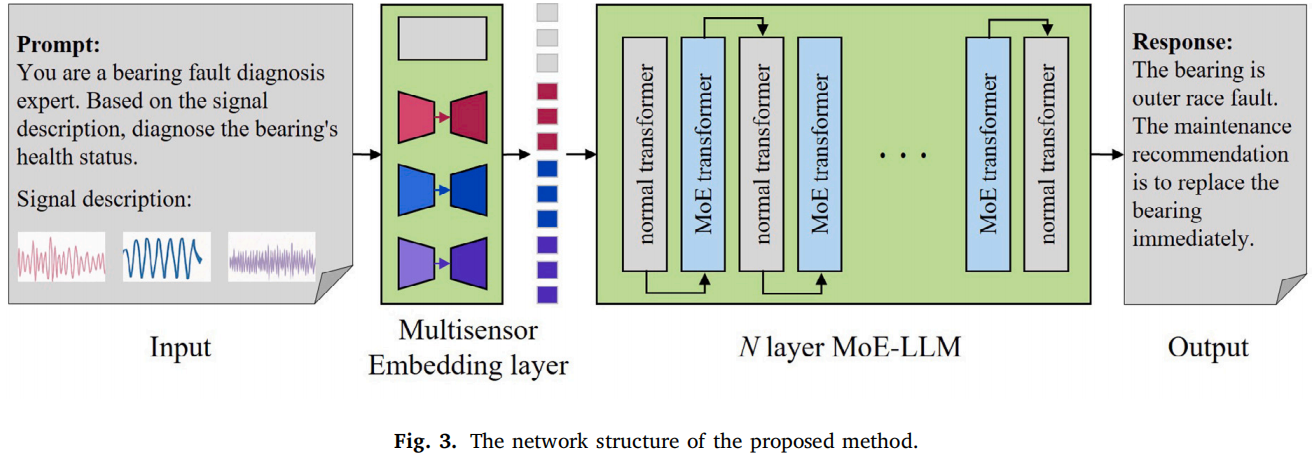
整体框架分成四部分:input prompt、多传感器 embedding 层、MoE-LLM 模块、output response。
多传感器 embedding 层负责把原始信号和文本变成 LLM 可接受的 embedding;MoE-LLM 通过稀疏 MoE 机制完成信号融合和故障诊断。
1. Multisensor Embedding Layer “大模型接口”
因为 LLM 本来处理的是文本 token,不是振动、电流、声学信号。所以作者设计了一个 embedding layer,把工业信号变成类似 token embedding 的形式。
原始信号
↓
预处理:重采样 + 功率归一化
↓
CNN特征提取器
↓
Connector对齐模块
↓
LLM-compatible embedding
具体来说,每种传感器都有自己的特征提取器 Ext_m,论文实现中用的是 5层 CNN。然后通过 connector,把 CNN 特征投影到 LLM 的 hidden dimension,再用 learnable query + multi-head attention 生成对齐后的 embedding。最后把传感器 embedding 和文本 prompt embedding 拼接起来输入 LLM。
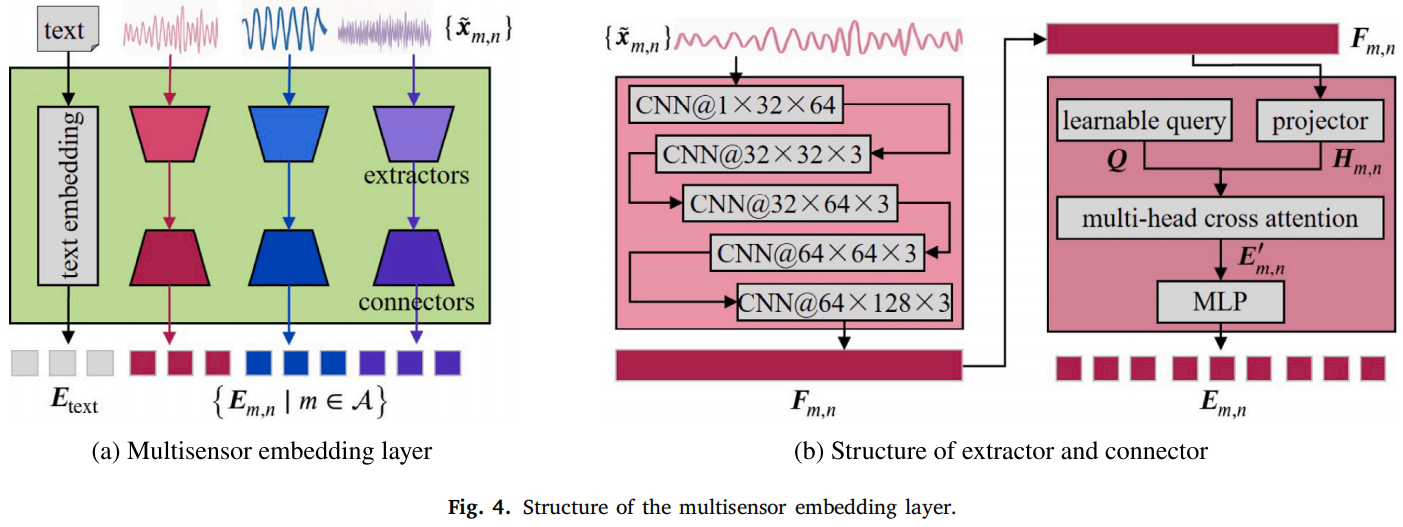
CNN 负责把信号变成特征;connector 负责把工业信号特征翻译成大模型能理解的“语言空间”。
2. MoE-LLM 模块
MoE 是 Mixture of Experts,混合专家模型。核心思想是:不是每次都让整个模型全部工作,而是由 router/gating network 根据输入选择几个最相关的专家。
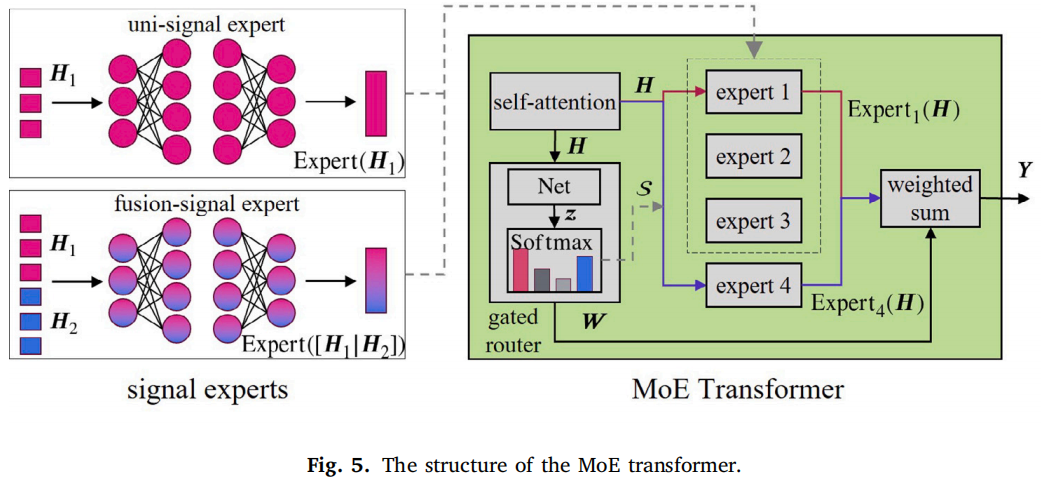
论文中的 MoE 由两部分组成:
专家网络:Expert 1, Expert 2, …
路由网络:决定当前输入该激活哪些专家数学上就是:
g = Gating(x)
y = Σ g_i · f_i(x)
其中 f_i 是第 i 个专家,g_i 是该专家的权重。MoE 的好处是:模型容量可以很大,但每次只激活少数专家,所以计算量不会线性增加。这篇文章的 MoE 设计比较有意思:
如果有 M 种传感器,那么构造 2^M - 1 个信号专家,每个专家对应一种非空传感器组合。比如 M=2,振动和电流,那么专家包括:
Expert 1:振动专家
Expert 2:电流专家
Expert 3:振动+电流融合专家
同时作者还保留了 Transformer 原来的 FFN 作为 text expert,因此总专家数变成 2^M。这样可以兼顾信号诊断能力和原始语言能力。
3. Base LLM
Backbone 是 DeepSeek-R1-Distill-Qwen-1.5B,也就是 1.5B 参数的大语言模型。它不是从零训练大模型,而是在已有 LLM 上做改造。
具体改造是:
原始 Transformer Block:Self-Attention + FFN
改造后部分 Transformer Block:Self-Attention + MoE Layer作者没有把所有 Transformer 层都换成 MoE,而是只改了第 4、8、12、16、20 层,一共 5 层。这样可以降低计算开销,同时引入多专家能力。
4. 训练策略
没有直接 end-to-end 训练,而是用了 curriculum learning-based staged training,也就是“课程学习式分阶段训练”。
- 分四步:
Stage 1:预训练每种传感器的 CNN 特征提取器
Stage 2:训练 connector,把信号特征对齐到 LLM embedding 空间
Stage 3:分别微调每个专家
Stage 4:插入 MoE 层,用 LoRA 进行任务微调
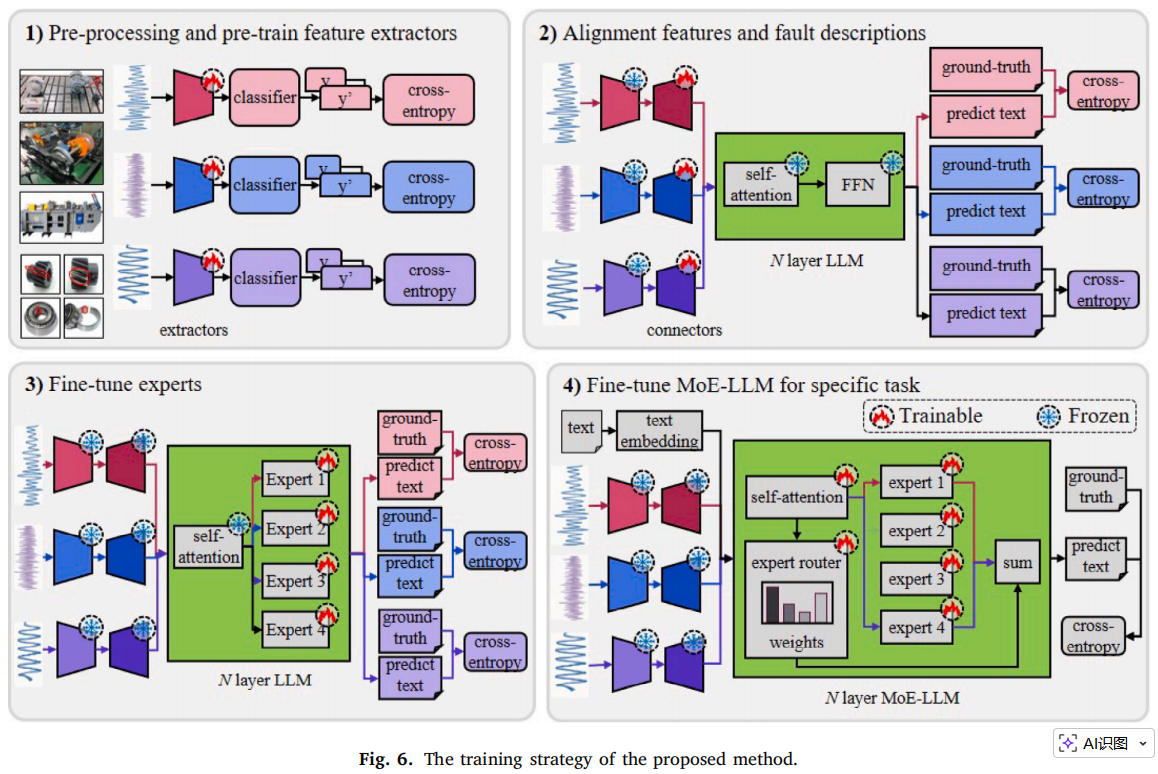
这个设计很重要,因为直接把工业信号、connector、MoE、LLM 全部一起训练,参数太多、很难收敛。分阶段训练相当于先让模型学会“看信号”,再学会“把信号翻译给大模型”,再学会“不同专家处理不同信号组合”,最后整体微调。
三、实验结果与分析
用了三个多传感器旋转机械数据集:
IB dataset:振动 + 声学
BJTU-A dataset:振动 + 电流
MB dataset:振动 + 声学

结果上,提出方法在三个数据集上的表现分别是:
IB:Acc 97.87%,F1 97.85%
BJTU-A:Acc 99.76%,F1 99.76%
MB:Acc 99.95%,F1 99.95%
为什么分析的还是小模型的指标?
📌 因为它把 LLM 当“分类器用”
虽然用了:LLM(DeepSeek),prompt,文本输出
但实际上:LLM ≈ 一个更复杂的 Transformer 分类器
👉 并没有真正用到:reasoning(推理)/multi-step inference(多步推理)/knowledge grounding(知识推理)
📌 本质 pipeline 是:信号 → embedding → Transformer → 输出token → 映射类别
👉 和普通 deep learning 的区别只是:backbone换成LLM,输出形式变成文本
任务本质:还是“故障分类”
虽然论文写的是:输出 = “诊断结果 + 文本解释”
但实际实验中,它做的是:
输入:多传感器信号
输出:一段文本(比如:outer race fault)
然后做了一个操作:👉 把生成的文本映射回类别标签
比如:
“outer race fault” → 类别 3
“inner race fault” → 类别 2
四、文章亮点与不足
亮点
第一,它不是简单把信号转文字喂给 LLM。
它保留了原始信号结构,用 CNN + connector 转成 embedding,这比“把信号统计量写成文本”更合理。
第二,MoE 专家和传感器组合绑定。
这点对多传感器故障诊断很有价值。振动、电流、声学信号物理含义不同,固定融合容易粗糙;MoE 允许模型根据输入情况动态选择专家。
第三,它支持 flexible fusion。
这对真实工业场景很重要,因为真实系统中传感器可能缺失、类型不同、组合不同。它比固定输入的多模态网络更灵活。
不足
第一,它说是 LLM,但本质上主要利用的是 LLM 的 Transformer backbone 和 embedding 空间,并没有真正深入利用大模型的工业知识推理能力。
第二,输出虽然是文本,但实验评估主要还是分类准确率和 F1,没有系统评估解释质量、推理可靠性、幻觉问题。
第三,MoE 专家数量会随着传感器类型指数增长。论文自己也承认,如果传感器类型增加,专家子网络数量可能快速膨胀,影响可扩展性。
第四,它没有解决多传感器真实场景中的时间不同步问题。论文也提到,虽然支持不同传感器组合,但没有显式处理 temporal misalignment 或 asynchronous sampling。



