No.13
标签:
前言
《Adaptive Modality Balanced Online Knowledge Distillation for Brain-Eye-Computer-Based Dim Object Detection》
期刊:IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS
年份:2025
分区:Q1,一区Top;IF:9.7
作者:Zixing Li, Chao Yan, Member, IEEE, Zhen Lan, Xiaojia Xiang, Han Zhou, Jun Lai, and Dengqing Tang
主要单位:College of Intelligence Science and Technology, National University of Defense Technology
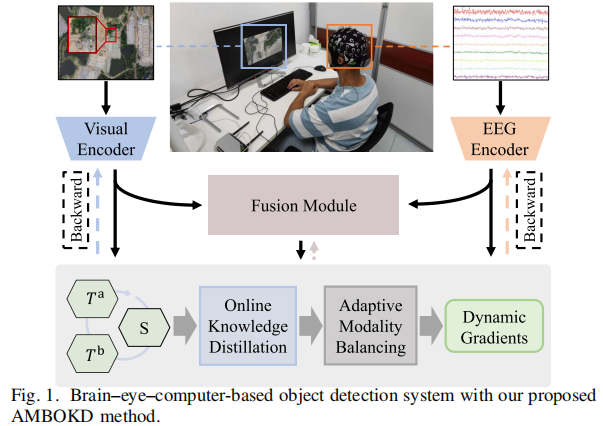
- 脑-眼-计算机协同目标检测:针对航空图像中的弱小目标检测,先用 RPN (Region Proposal Network) 找候选区域,再让被试通过眼动引导的慢速视觉呈现范式观察候选区域,采集 EEG + 眼动 + 图像配对数据,最后用一种自适应模态平衡的在线知识蒸馏方法 AMBOKD 融合 EEG 和图像特征,提高少样本条件下的目标识别性能。
一、研究背景与问题定位
1. 背景
- 航空图像里的目标往往很小、很暗、背景复杂、视角变化大,而且在军事侦察、灾害救援这类场景中,训练样本很少,所以纯 CV 方法容易漏检或误检。
- 另一方面,纯 EEG 方法虽然能利用人的认知能力,比如 ERP/P300 对目标的反应,但 EEG 噪声大、个体差异大,单独用 EEG 准确率不够。
2. 问题定位
- 如何在少样本航空弱小目标检测场景中,把机器视觉的特征提取能力和人的视觉认知能力结合起来?
二、文章解读
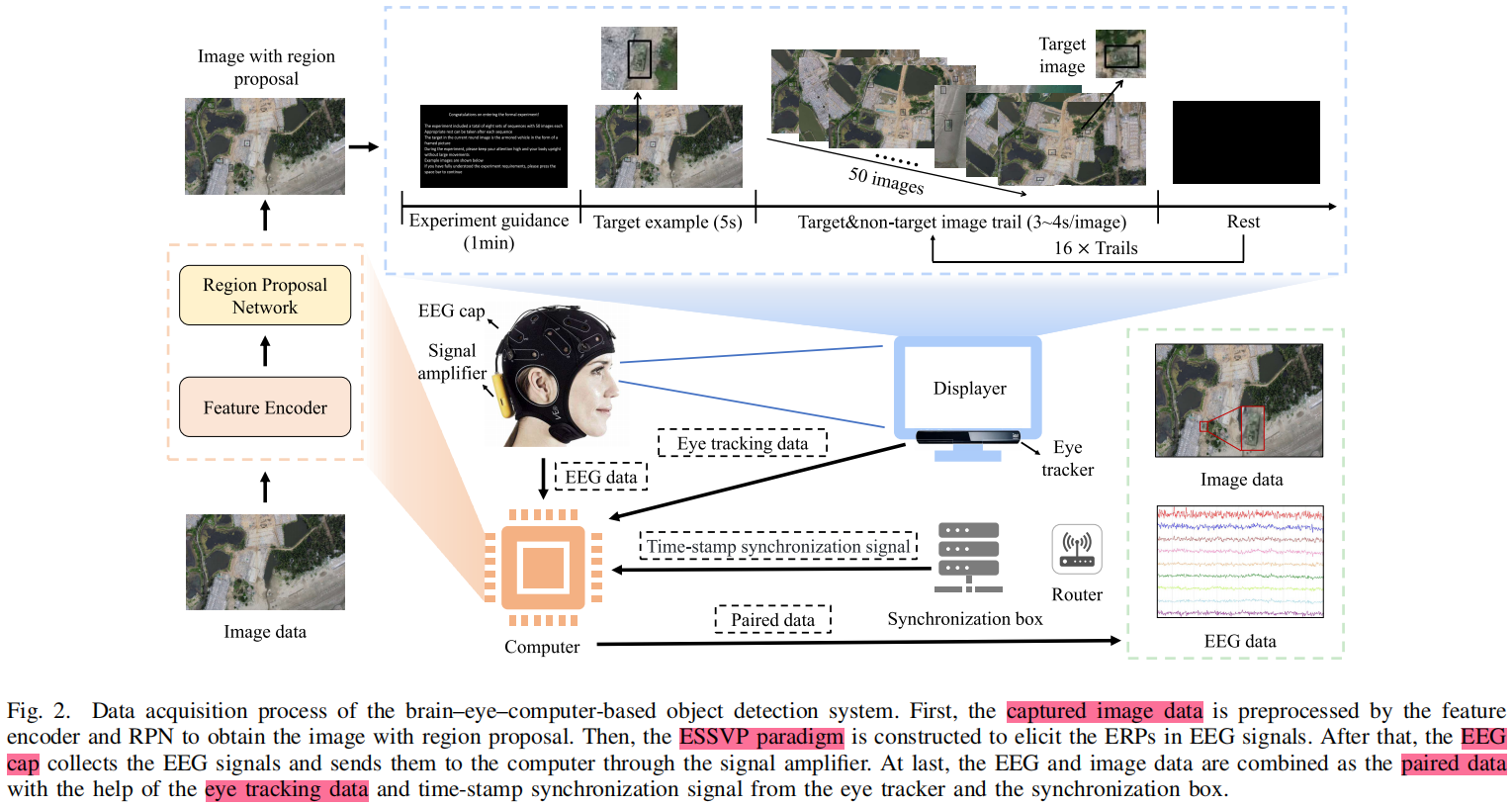
1. RPN + ESSVP + EEG/眼动配对流程
第一步,计算机先用 ResNet-50 + RPN 在航空图像中生成候选区域,也就是 suspicious region。
RPN anchor 的尺度是 16、32、48、64、80,长宽比是 0.5、0.75、1.0、1.5、2.0。
第二步,把带有候选区域的图像通过 ESSVP 范式呈现给被试。
ESSVP 是 Eye-tracking-based Slow Serial Visual Presentation,可以理解为“眼动辅助的慢速 RSVP”。
它不是快速闪图,而是每张图显示 3–4 秒,让被试有时间搜索弱小目标。
第三步,用眼动仪记录被试看哪里。如果被试看某个候选框超过 0.3 s,就记录这个候选框和对应图像,同时发送 fixation trigger 给 EEG 系统,截取对应时间段的脑电。这样就能构造 EEG–image paired data。
第四步,把候选图像 patch 和对应 EEG 输入 AMBOKD 模型,判断该候选区域是不是目标。
最后再根据眼动数据把目标位置映射回原图,实现目标检测。
所以它所谓的 object detection,本质上是:
候选框生成 + 脑眼图像多模态候选区域分类 + 位置回映射。
2. ESSVP范式具体设计
正式实验中,每个被试看 16 个序列,每个序列 50 张图像。序列分成两个 session。
每个 session 前 6 个序列是简单场景里的玩具模型,比如装甲车、飞机,每张图 3 s;
后 2 个序列是真实复杂场景,每张图 4 s。前 6 个序列目标是装甲模型,后 2 个序列目标是车辆。
目标出现概率设到了 40%,并在连续目标之间随机插入 1–2 张非目标图像,避免连续目标造成 attentional blink。
每个候选区域要求被试至少注视 0.5 s。

3. 数据集和预处理
采集了 10 名被试,6 男 4 女,22–26 岁,右利手,正常或矫正视力。
EEG 采样率 1000 Hz,64 个湿电极,10–20 系统,阻抗低于 10 kΩ。
最终数据集包含 13,405 个样本,其中 3,880 个正样本,9,525 个负样本,目标比例 28.9%。
- EEG 实际使用 59 个通道,5 个冗余电极去掉。预处理是 2–30 Hz 带通滤波,1000 Hz 降采样到 250 Hz,以 trigger 为基准截取 −500 到 700 ms,共 1.2 s,前 200 ms 做 baseline correction。
- 图像 patch 最小 150×150,统一 resize 到 224×224。验证集里还人为加入 Gaussian noise 和 salt-and-pepper noise 来模拟实际噪声。
因此模型输入是:
EEG:59 × 300
Image:3 × 224 × 224
4. AMBOKD 模型
AMBOKD 可以拆成四个部分:
第一,图像编码器。
作者用 EfficientNet-B0 做 visual encoder,并用 ImageNet 预训练参数初始化。它主要输出视觉特征。第二,EEG 编码器。
作者用 MCGRAM 做 EEG encoder。MCGRAM 是他们前作里的 EEG 网络,包括频率编码、空间图卷积、时间 LSTM + self-attention,用来提取 EEG 的频谱、空间和时间特征。第三,多头注意力融合。
EEG 特征和图像特征先通过全连接层对齐到相同维度,然后 concat,再用 multi-head self-attention 学习 EEG 和 image 之间的重要性关系,得到 fusion feature。作者把这个 fusion branch 当作第三个“模态”。第四,在线知识蒸馏 + 自适应模态平衡。
这是文章真正的方法创新。它不是简单 concat 后分类,而是让 Image branch、EEG branch、Fusion branch 三个分支互相学习。每个分支轮流当 student,另外两个分支当 teacher,loss 包括 CE loss 和 KD loss。
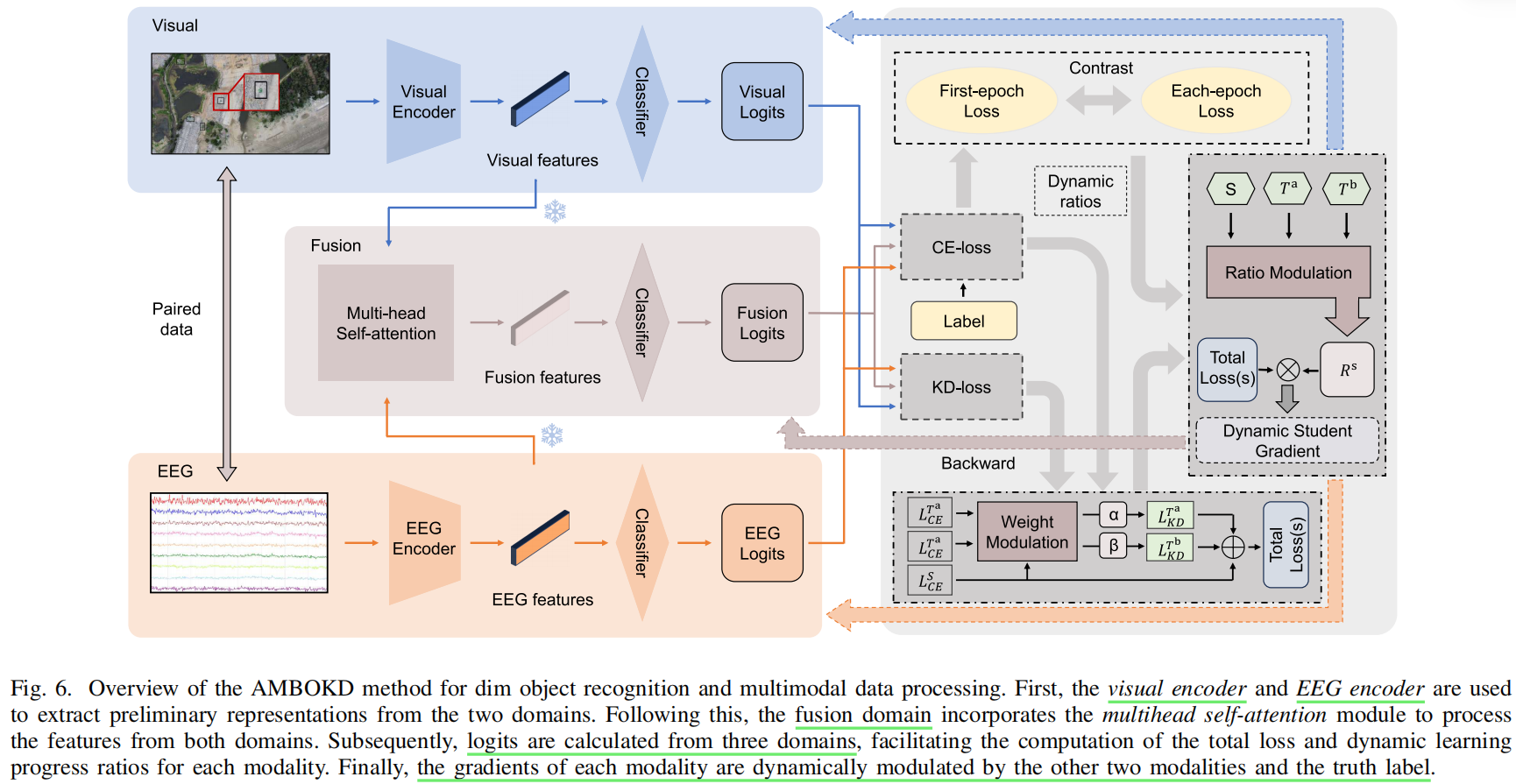
它的关键想法是:
- 图像模态、EEG 模态、融合模态的学习速度不一样。
图像通常收敛快,EEG 噪声大、收敛慢。如果不控制,强模态会主导训练,弱模态学不好。
因此要动态调节各模态的蒸馏权重和梯度更新强度。
AMB 模块有两个机制:
- 一个是 dynamic weights for KD losses,根据 student 和 teacher 的 CE loss 比例动态调节 KD loss 权重 α、β。
简单说,哪个 teacher 当前更可靠,它对 student 的蒸馏影响就更大。 - 另一个是 dynamic ratios for backward gradients,根据各模态的学习进度动态调节梯度更新比例,避免某个模态过快收敛、另一个模态训练不足。
5. 实验设计
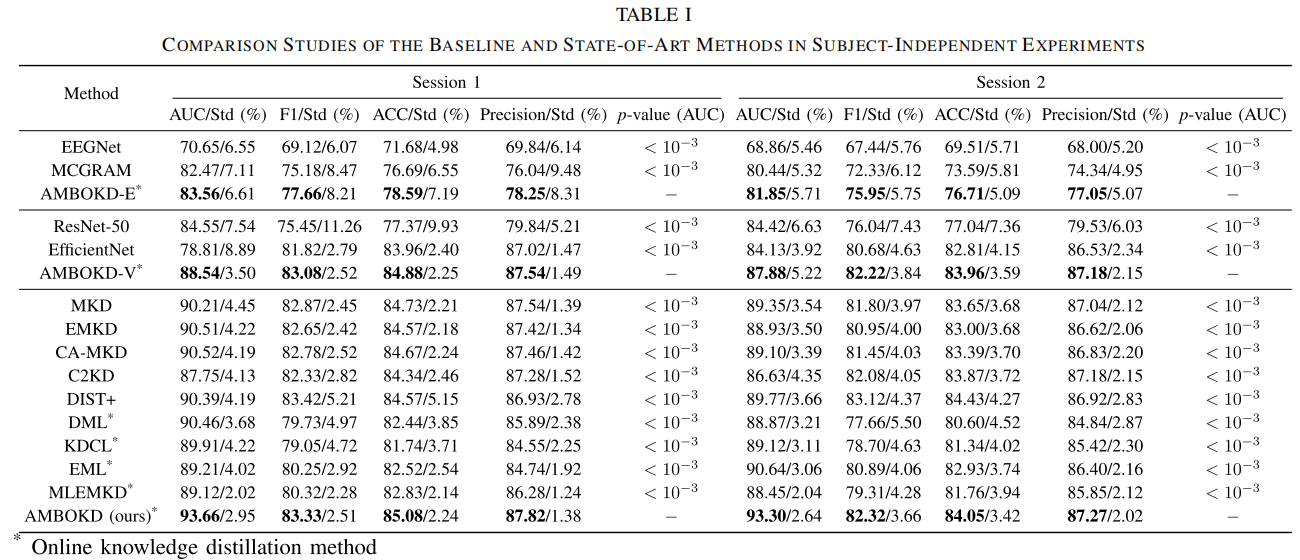
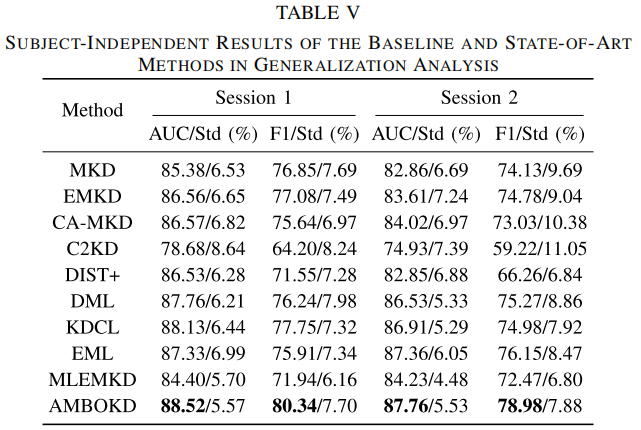
- 第一类是 ESSVP 自建数据集上的 subject-independent 实验。
每一折拿 1 个被试做验证,另外 9 个被试训练,相当于 leave-one-subject-out,再用 5 个随机种子求平均。
指标包括 AUC、ACC、F1、Precision。由于正负样本不平衡,作者强调 AUC 是主指标。
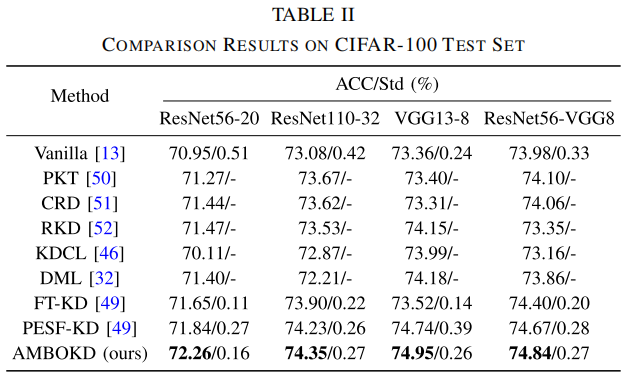
- 第二类是 CIFAR-100 实验,用来证明 AMBOKD 不只适用于 EEG-image,也能用于通用知识蒸馏。
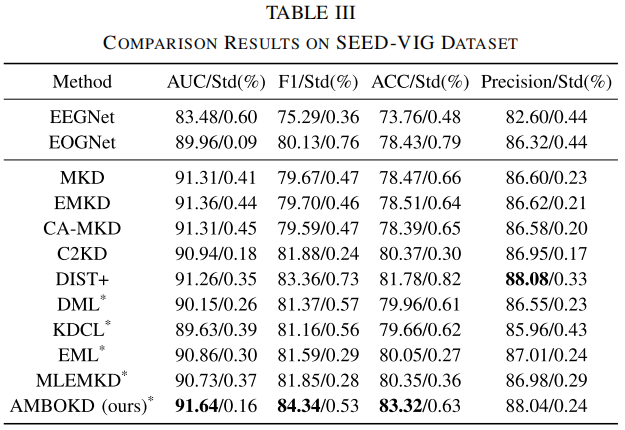
- 第三类是 SEED-VIG 多模态疲劳驾驶数据集,用 EEG + EOG 做验证,说明方法有一定跨任务泛化性。
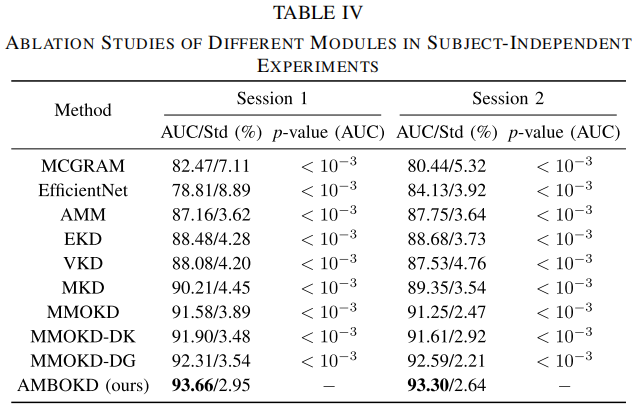
- 第四类是消融实验,逐步去掉 multi-head attention、KD、online mutual learning、dynamic KD weights、dynamic gradient modulation 等模块。
- 第五类是从简单场景到复杂场景的迁移实验,用 30 个真实场景样本微调,然后在真实复杂场景测试。
- 第六类是 physical verification,也就是实际系统验证。被试坐在电脑前,一边执行 ESSVP,一边模拟 AAV 地面站监控任务。
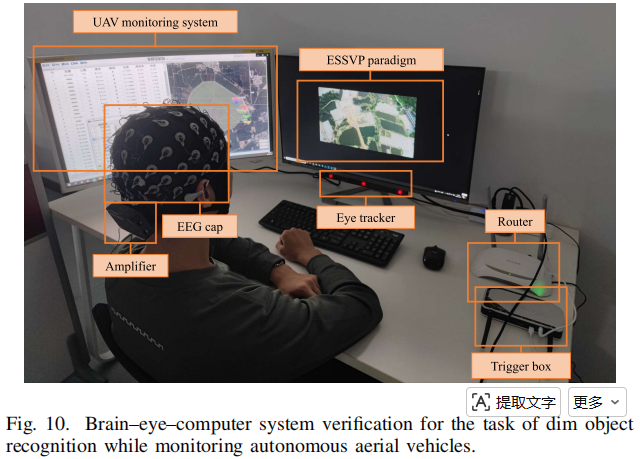
6. 文章贡献
第一,系统贡献。它不是只做算法,而是搭了一个脑-眼-计算机闭环式弱小目标检测系统:RPN 候选区域、ESSVP 呈现、眼动定位、EEG 认知反应、融合模型识别。
第二,数据贡献。他们构建并公开了一个 ESSVP 数据集,包含航空图像、眼动定位和 EEG-image 配对数据。这对脑机视觉融合方向是有价值的。
第三,训练方法贡献。AMBOKD 的重点是解决多模态训练不平衡:图像强、EEG 弱;图像快、EEG 慢;融合分支容易被强模态主导。所以它用在线知识蒸馏让三个分支互学,再用自适应权重和动态梯度平衡学习过程。
7. 局限性
第一个问题:它叫 object detection,但模型核心其实是 candidate-level recognition。
真正的定位主要靠 RPN 和眼动回映射,AMBOKD 本身是在判断候选区域是不是目标。严格讲,它不是端到端目标检测器。第二个问题:ESSVP 太慢。
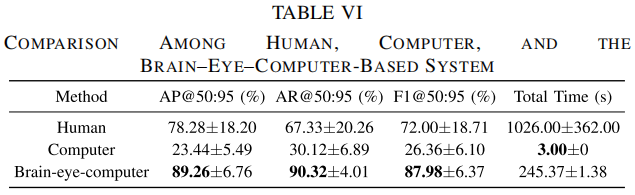
物理验证中总耗时 245.37 s,其中 ESSVP 就占 240 s。对“无人机实时侦察”来说,这个实时性显然不够。
作者自己也在 conclusion 里承认目前系统是 offline setting,未来要做 real-time online system。第三个问题:被试数量少且同质化。
只有 10 个大学生,年龄 22–26 岁。虽然做了 subject-independent,但泛化到真实操作者、疲劳状态、不同经验人群,还不好说。第四个问题:任务设计可能有一定范式依赖。
被试提前知道目标类型,并且每个候选区域注视 0.5 s,眼动 trigger 又参与样本构造。
这种情况下,EEG 反映的是“主动搜索和确认目标”的脑反应,不完全等价于无意识快速视觉注意。第五个问题:纯 CV baseline 在物理验证里表现太差,可能让脑-眼-计算机系统优势显得更大。
Table VI 里纯计算机 AP@50:95 只有 23.44%,这是因为只有 30 个真实样本微调,确实少样本。但如果换更强的 few-shot detector 或 foundation model,差距可能会缩小。第六个问题:多模态蒸馏方法比较复杂,但生理解释不够强。
AMBOKD 主要是工程训练策略,虽然用了 EEG,但它没有深入分析 ERP 波形、时空脑区贡献、眼动行为和 EEG 的对应关系。
对脑机接口论文来说,生理机制部分偏弱。
8. 启发
“模态不平衡” 问题值得写进论文。
EEG-image fusion 中不同模态可靠性和收敛速度不同,简单 concat 或固定权重容易导致强模态主导。这可以支持你设计 contrastive alignment、auxiliary loss 或 modality-balanced fusion。



