No.14
标签:
前言
《Mind-pinyin speller: A non-invasive brain-computer interface for efficient Chinese character input using EEG-based imagined handwriting》
期刊:Expert Systems With Applications
年份:2026
分区:Q1,一区Top;IF:9.4
作者:Lingyu Wu, Tzyy-Ping Jung, Xiaojian Li, Yanhong Zhou, Xianglong Wan, Wenlong Jiao, Xueguang Xie, Dingna Duan, Tiange Liu, Hao Yu, Danyang Li, Xiaoling Li, Zhenzhen Wu, Jing Wang, Haiqing Song, Dong Wen
主要单位:School of Intelligence Science and Technology, University of Science and Technology Beijing
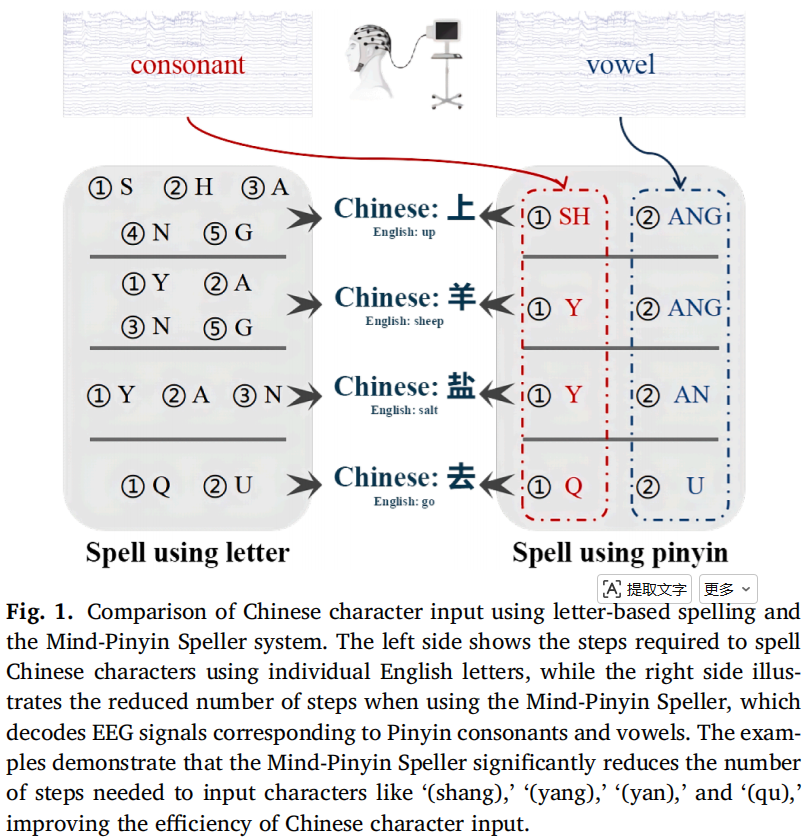
- 让被试想象书写拼音声母和韵母,然后用 EEG 解码出对应的拼音元素,再组合成中文输入。
一、研究背景与问题定位
1. 背景
- 面向中文交流障碍人群,针对现有非侵入式 BCI 拼写器在中文输入中效率低、视觉刺激依赖强、语言适配不足的问题,提出一种基于 EEG 想象书写的主动式拼音输入系统,通过解码 23 个声母和 23 个韵母来实现更高效的中文字符输入。
运动/语言障碍患者需要交流辅助
↓
侵入式 BCI 性能高,但风险高、成本高、难普及
↓
非侵入式 EEG-BCI 更安全,但语言输入速度和准确率不足
↓
现有 BCI Speller 多面向英文/字母系统,中文适配不足
↓
中文直接汉字解码太难,字母式拼写又效率低
↓
利用拼音结构,把中文输入拆成声母 + 韵母
↓
通过想象书写声母/韵母产生 EEG,并进行分类
↓
构建 Mind-Pinyin Speller,实现面向中文的非侵入式主动输入系统
2. 问题定位
巧妙避开了难点
- 第一,它没有直接做“汉字识别”。直接从 EEG 识别几千个汉字基本不现实,所以它降维成声母/韵母识别。
- 第二,它没有做传统 SSVEP/P300 拼写器。传统视觉刺激拼写器容易被审稿人认为缺乏新意,而且有视觉疲劳问题。它改成“imagined handwriting”,就有主动式范式的新鲜感。
- 第三,它没有只写算法。它把算法放在“中文输入系统”里,形成完整应用闭环。ESWA 很吃这一套。
二、文章解读
1. 完整技术路线
想象书写范式 → EEG采集 → 预处理 → Pairwise CSP特征提取 → CFAN分类 → 声母/韵母输出 → 拼音输入
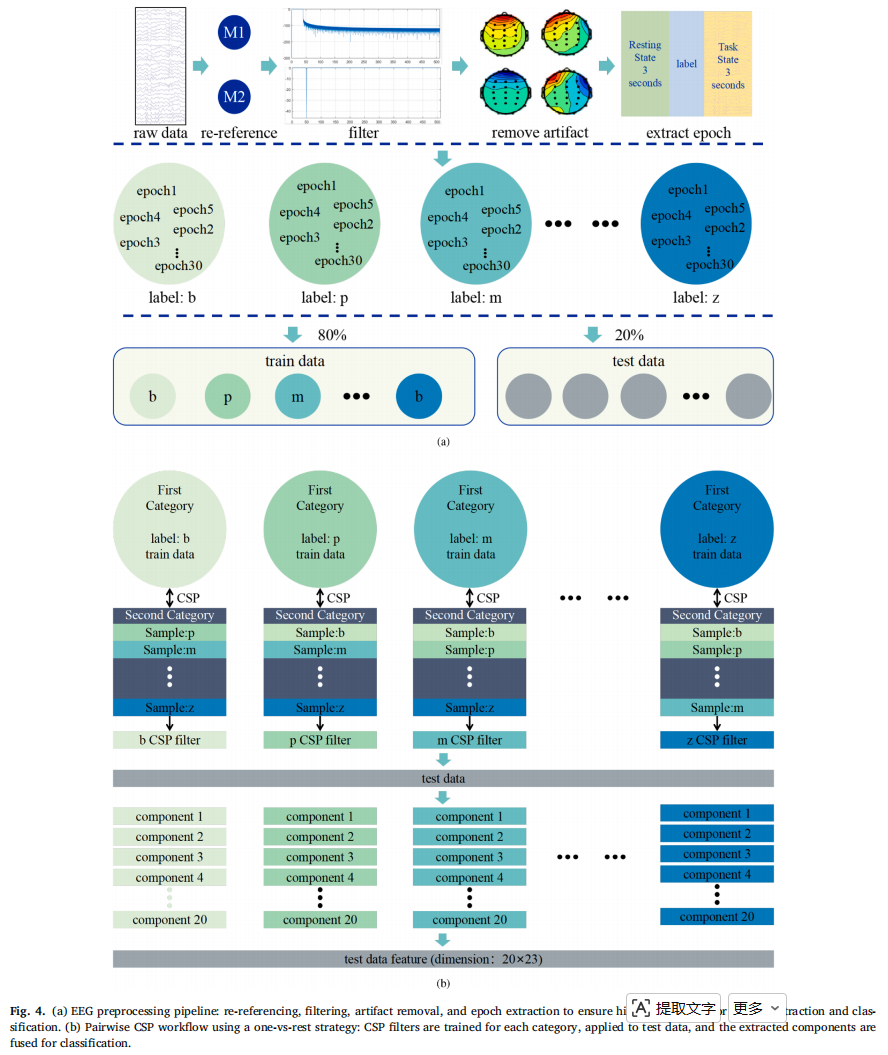
(1)实验上,作者招募了 15 名被试,年龄 21–28 岁,使用 32 通道 Neuroscan,采样率 512 Hz。每个 epoch 包括 3 秒 resting state 和 3 秒 task state。被试分别完成 23 个声母和 23 个韵母的想象书写任务,每个音素 30 个 epoch。声母和韵母分两天采集。
(2)数据预处理包括:
- 双侧乳突 M1/M2 重参考;
- 0.5–40 Hz 五阶 Butterworth 带通滤波;
- 50 Hz 陷波;
- ICA 去眼动和肌电伪迹;
- 切分 task-state epoch;
- 每类样本 80% 训练,20% 测试。
(3)然后作者用了所谓 Pairwise CSP 做特征提取。
CSP 原本是二分类空间滤波方法,作者把它扩展到多类分类。
每个测试样本经过所有 CSP filter 提取特征,每个 filter 保留 20 个 component,最后形成 23×20 的特征输入分类器。
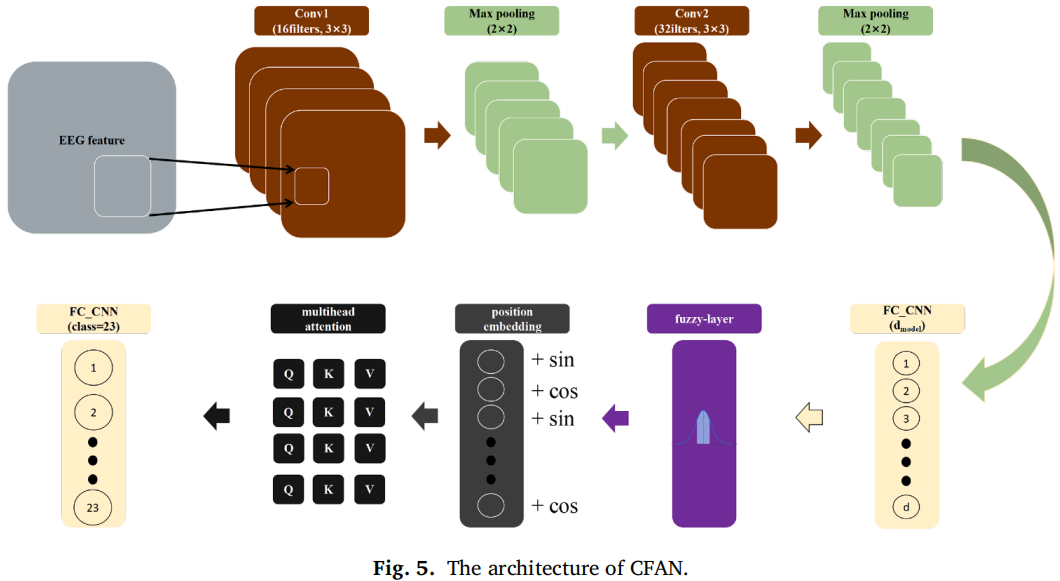
(4)分类器叫 CFAN:CNN-Fuzzy-Attention Network。它由三部分组成:
- 1D CNN:提取局部特征;
- Fuzzy layer:用 Gaussian membership function 处理 EEG 特征的不确定性;
- Transformer attention:建模全局依赖;
- 最后 FC 分类。
所以它不是“端到端从原始 EEG 解码”,而是:先用 CSP 做人工特征,再用 CNN + fuzzy + attention 分类。
2. 主要结果
作者报告的核心结果是:
- 声母平均准确率:71.73%
- 韵母平均准确率:79.87%
- 平均准确率:75.7%
- 声母 ITR:149.0 bits/min
- 韵母 ITR:178.85 bits/min
- 总体宣称 ITR:约 160 bits/min
- 声明可达到 10 个汉字/分钟
文章还给出了 Kappa:
- 声母 Kappa:0.69
- 韵母 Kappa:0.78
作者认为这说明系统超过随机水平,而且具备一定实用性。
此外,Table 1 显示不同被试差异很大。例如 S10 声母 93%、韵母 97%,但 S4 声母只有 36%,S8 声母和韵母都只有 49%。这说明这个系统并不是所有人都好用,个体差异非常明显。
3. 文章亮点
没有硬说“我能直接脑控输入中文”
它其实只做了“声母/韵母识别”,但是把它包装成中文输入系统。
因为直接识别汉字太难,中文常用汉字几千个,非侵入 EEG 根本不现实。作者通过拼音拆分,把问题变成两个 23 类分类任务。避开了 SSVEP/P300 的传统路线
传统 BCI spelling 很多是 SSVEP、P300、cVEP。它们通常需要视觉刺激,比如闪烁、矩阵刺激、目标注视等。
作者强调这些方法可能带来视觉疲劳,甚至对癫痫敏感人群有风险。于是作者提出“active imagined handwriting”,也就是主动想象书写,不依赖持续视觉闪烁。
这个叙事对审稿人很有效:
不是又做一个 SSVEP 拼写器,而是做一个主动式、非闪烁、中文专用的 BCI 输入系统。
- 把“中文语言特点”写成了核心贡献
这篇文章最强的不是神经机制,而是语言应用切入点。
它说:英文是 phonetic language,中文是 logographic language,现有非侵入式 BCI 语言解码主要集中在英文等拼音文字,对中文覆盖不足。于是它用拼音系统中的声母和韵母来桥接 EEG 解码和中文输入。
这就是它能发 ESWA 的关键。ESWA 喜欢这种:
某个实际领域存在具体问题 → 设计一个智能系统 → 用机器学习方法解决 → 给出实验验证。
4. 思考
- 拼写到底怎么执行?
真实执行流程应该是:
第 1 步:用户想象书写声母,比如 sh
↓
EEG 采集 3 秒 task-state
↓
声母分类模型输出:sh
第 2 步:用户想象书写韵母,比如 ang
↓
EEG 采集 3 秒 task-state
↓
韵母分类模型输出:ang
第 3 步:系统组合成拼音:sh + ang = shang
↓
理论上再进入中文候选字选择
论文其实没有完整实现中文候选字选择。它主要验证的是声母/韵母 EEG 分类,不是真正完整的中文输入法。
- 非侵入式 EEG 怎么“解码出音节”?
实验范式是“提示式分类”,不是自由拼写
文章在分析混淆类别时说,虽然被试是在 imagined writing,但他们可能在书写过程中 subconsciously murmured,也就是潜意识里轻声念/默念。作者认为这可能导致一些书写形式不同但发音方式类似的拼音被混淆,比如 p、k、m 等。
这其实等于承认:
他们解码到的东西未必是纯想象书写,也可能混入了 imagined speech、subvocalization、口腔/喉部肌电、发音准备等成分。
传统 MI 通常是:想象左手运动 vs 想象右手运动 → 看 C3/C4 附近 μ/β 节律 ERD/ERS,
这种信号弱、个体差异大、训练困难,所以二分类都不容易。
文章 limitations 里说,运动想象范式存在 MI illiteracy,也就是一部分人无法有效使用自发神经编码,只能依赖外源性编码;这些人没有有效训练可能无法使用该系统。
作者还承认当前主要是 offline experiments,真实应用需要 online settings 验证,并且离线到在线还要解决实时信号处理和 EEG 伪迹问题。



